Causal Attributions and Root-Cause Analysis in an Online Shop#
This notebook is an extended and updated version of the corresponding blog post: Root Cause Analysis with DoWhy, an Open Source Python Library for Causal Machine Learning
In this example, we look at an online store and analyze how different factors influence our profit. In particular, we want to analyze an unexpected drop in profit and identify the potential root cause of it. For this, we can make use of Graphical Causal Models (GCM).
The scenario#
Suppose we are selling a smartphone in an online shop with a retail price of $999. The overall profit from the product depends on several factors, such as the number of sold units, operational costs or ad spending. On the other hand, the number of sold units, for instance, depends on the number of visitors on the product page, the price itself and potential ongoing promotions. Suppose we observe a steady profit of our product over the year 2021, but suddenly, there is a significant drop in profit at the beginning of 2022. Why?
In the following scenario, we will use DoWhy to get a better understanding of the causal impacts of factors influencing the profit and to identify the causes for the profit drop. To analyze our problem at hand, we first need to define our belief about the causal relationships. For this, we collect daily records of the different factors affecting profit. These factors are:
Shopping Event?: A binary value indicating whether a special shopping event took place, such as Black Friday or Cyber Monday sales.
Ad Spend: Spending on ad campaigns.
Page Views: Number of visits on the product detail page.
Unit Price: Price of the device, which could vary due to temporary discounts.
Sold Units: Number of sold phones.
Revenue: Daily revenue.
Operational Cost: Daily operational expenses which includes production costs, spending on ads, administrative expenses, etc.
Profit: Daily profit.
Looking at these attributes, we can use our domain knowledge to describe the cause-effect relationships in the form of a directed acyclic graph, which represents our causal graph in the following. The graph is shown here:
[1]:
from IPython.display import Image
Image('online-shop-graph.png')
[1]:
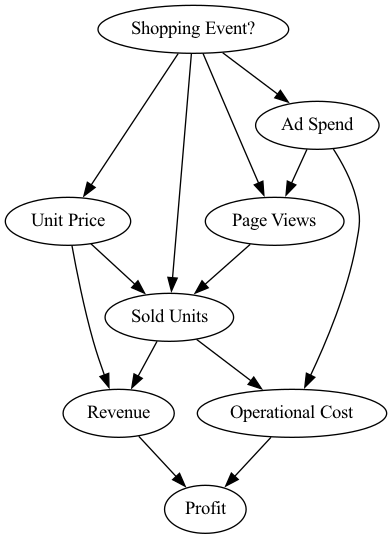
In this scenario we know the following:
Step 1: Define causal model#
Now, let us model these causal relationships. In the first step, we need to define a so-called structural causal model (SCM), which is a combination of the causal graph and the underlying generative models describing the data generation process.
The causal graph can be defined via:
[2]:
import networkx as nx
causal_graph = nx.DiGraph([('Page Views', 'Sold Units'),
('Revenue', 'Profit'),
('Unit Price', 'Sold Units'),
('Unit Price', 'Revenue'),
('Shopping Event?', 'Page Views'),
('Shopping Event?', 'Sold Units'),
('Shopping Event?', 'Unit Price'),
('Shopping Event?', 'Ad Spend'),
('Ad Spend', 'Page Views'),
('Ad Spend', 'Operational Cost'),
('Sold Units', 'Revenue'),
('Sold Units', 'Operational Cost'),
('Operational Cost', 'Profit')])
To verify that we did not forget an edge, we can plot this graph:
[3]:
from dowhy.utils import plot
plot(causal_graph)
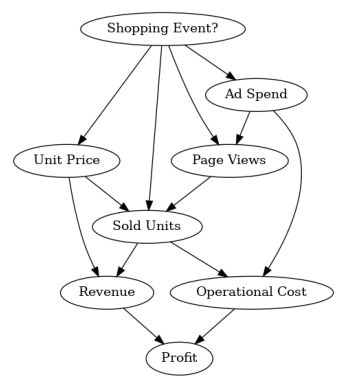
Next, we look at the data from 2021:
[4]:
import pandas as pd
import numpy as np
pd.options.display.float_format = '${:,.2f}'.format # Format dollar columns
data_2021 = pd.read_csv('2021 Data.csv', index_col='Date')
data_2021.head()
[4]:
| Shopping Event? | Ad Spend | Page Views | Unit Price | Sold Units | Revenue | Operational Cost | Profit | |
|---|---|---|---|---|---|---|---|---|
| Date | ||||||||
| 2021-01-01 | False | $1,490.49 | 11861 | $999.00 | 2317 | $2,314,683.00 | $1,659,999.89 | $654,683.11 |
| 2021-01-02 | False | $1,455.92 | 11776 | $999.00 | 2355 | $2,352,645.00 | $1,678,959.08 | $673,685.92 |
| 2021-01-03 | False | $1,405.82 | 11861 | $999.00 | 2391 | $2,388,609.00 | $1,696,906.14 | $691,702.86 |
| 2021-01-04 | False | $1,379.30 | 11677 | $999.00 | 2344 | $2,341,656.00 | $1,673,380.64 | $668,275.36 |
| 2021-01-05 | False | $1,234.20 | 11871 | $999.00 | 2412 | $2,409,588.00 | $1,707,252.61 | $702,335.39 |
As we see, we have one sample for each day in 2021 with all the variables in the causal graph. Note that in the synthetic data we consider here, shopping events were also generated randomly.
We defined the causal graph, but we still need to assign generative models to the nodes. We can either manually specify those models, and configure them if needed, or automatically infer “appropriate” models using heuristics from data. We will leverage the latter here:
[5]:
from dowhy import gcm
gcm.util.general.set_random_seed(0)
# Create the structural causal model object
scm = gcm.StructuralCausalModel(causal_graph)
# Automatically assign generative models to each node based on the given data
auto_assignment_summary = gcm.auto.assign_causal_mechanisms(scm, data_2021)
Whenever available, we recommend assigning models based on prior knowledge as then models would closely mimic the physics of the domain, and not rely on nuances of the data. However, here we asked DoWhy to do this for us instead.
After automatically assign the models, we can print a summary to obtain some insights into the selected models:
[6]:
print(auto_assignment_summary)
When using this auto assignment function, the given data is used to automatically assign a causal mechanism to each node. Note that causal mechanisms can also be customized and assigned manually.
The following types of causal mechanisms are considered for the automatic selection:
If root node:
An empirical distribution, i.e., the distribution is represented by randomly sampling from the provided data. This provides a flexible and non-parametric way to model the marginal distribution and is valid for all types of data modalities.
If non-root node and the data is continuous:
Additive Noise Models (ANM) of the form X_i = f(PA_i) + N_i, where PA_i are the parents of X_i and the unobserved noise N_i is assumed to be independent of PA_i.To select the best model for f, different regression models are evaluated and the model with the smallest mean squared error is selected.Note that minimizing the mean squared error here is equivalent to selecting the best choice of an ANM.
If non-root node and the data is discrete:
Discrete Additive Noise Models have almost the same definition as non-discrete ANMs, but come with an additional constraint for f to only return discrete values.
Note that 'discrete' here refers to numerical values with an order. If the data is categorical, consider representing them as strings to ensure proper model selection.
If non-root node and the data is categorical:
A functional causal model based on a classifier, i.e., X_i = f(PA_i, N_i).
Here, N_i follows a uniform distribution on [0, 1] and is used to randomly sample a class (category) using the conditional probability distribution produced by a classification model.Here, different model classes are evaluated using the (negative) F1 score and the best performing model class is selected.
In total, 8 nodes were analyzed:
--- Node: Shopping Event?
Node Shopping Event? is a root node. Therefore, assigning 'Empirical Distribution' to the node representing the marginal distribution.
--- Node: Unit Price
Node Unit Price is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using LinearRegression' to the node.
This represents the causal relationship as Unit Price := f(Shopping Event?) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
LinearRegression: 142.77431246551515
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 142.78271703597315
HistGradientBoostingRegressor: 439.63843778273156
--- Node: Ad Spend
Node Ad Spend is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using LinearRegression' to the node.
This represents the causal relationship as Ad Spend := f(Shopping Event?) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
LinearRegression: 15950.378625434218
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 16057.728423653647
HistGradientBoostingRegressor: 80313.4296584338
--- Node: Page Views
Node Page Views is a non-root node with discrete data. Assigning 'Discrete AdditiveNoiseModel using Pipeline' to the node.
This represents the discrete causal relationship as Page Views := f(Ad Spend,Shopping Event?) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 83938.3537814653
LinearRegression: 85830.1184468119
HistGradientBoostingRegressor: 1428896.628193814
--- Node: Sold Units
Node Sold Units is a non-root node with discrete data. Assigning 'Discrete AdditiveNoiseModel using LinearRegression' to the node.
This represents the discrete causal relationship as Sold Units := f(Page Views,Shopping Event?,Unit Price) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
LinearRegression: 8904.890796950855
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 14157.831817904153
HistGradientBoostingRegressor: 231668.29855446037
--- Node: Revenue
Node Revenue is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using Pipeline' to the node.
This represents the causal relationship as Revenue := f(Sold Units,Unit Price) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 1.0800435888102176e-18
LinearRegression: 69548987.23197266
HistGradientBoostingRegressor: 155521789447.02286
--- Node: Operational Cost
Node Operational Cost is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using LinearRegression' to the node.
This represents the causal relationship as Operational Cost := f(Ad Spend,Sold Units) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
LinearRegression: 38.71409364534825
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 39.01584891167706
HistGradientBoostingRegressor: 18332123695.022976
--- Node: Profit
Node Profit is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using LinearRegression' to the node.
This represents the causal relationship as Profit := f(Operational Cost,Revenue) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
LinearRegression: 1.852351985649207e-18
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 2.8418485593830953e-06
HistGradientBoostingRegressor: 22492460598.32865
===Note===
Note, based on the selected auto assignment quality, the set of evaluated models changes.
For more insights toward the quality of the fitted graphical causal model, consider using the evaluate_causal_model function after fitting the causal mechanisms.
As we see, while the auto assignment also considered non-linear models, a linear model is sufficient for most relationships, except for Revenue, which is the product of Sold Units and Unit Price.
Step 2: Fit causal models to data#
After assigning a model to each node, we need to learn the parameters of the model:
[7]:
gcm.fit(scm, data_2021)
Fitting causal mechanism of node Operational Cost: 100%|██████████| 8/8 [00:00<00:00, 365.79it/s]
The fit method learns the parameters of the generative models in each node. Before we continue, let’s have a quick look into the performance of the causal mechanisms and how well they capture the distribution:
[8]:
print(gcm.evaluate_causal_model(scm, data_2021, compare_mechanism_baselines=True, evaluate_invertibility_assumptions=False, evaluate_causal_structure=False))
Evaluating causal mechanisms...: 100%|██████████| 8/8 [00:00<00:00, 882.76it/s]
Evaluated the performance of the causal mechanisms and the overall average KL divergence between generated and observed distribution. The results are as follows:
==== Evaluation of Causal Mechanisms ====
The used evaluation metrics are:
- KL divergence (only for root-nodes): Evaluates the divergence between the generated and the observed distribution.
- Mean Squared Error (MSE): Evaluates the average squared differences between the observed values and the conditional expectation of the causal mechanisms.
- Normalized MSE (NMSE): The MSE normalized by the standard deviation for better comparison.
- R2 coefficient: Indicates how much variance is explained by the conditional expectations of the mechanisms. Note, however, that this can be misleading for nonlinear relationships.
- F1 score (only for categorical non-root nodes): The harmonic mean of the precision and recall indicating the goodness of the underlying classifier model.
- (normalized) Continuous Ranked Probability Score (CRPS): The CRPS generalizes the Mean Absolute Percentage Error to probabilistic predictions. This gives insights into the accuracy and calibration of the causal mechanisms.
NOTE: Every metric focuses on different aspects and they might not consistently indicate a good or bad performance.
We will mostly utilize the CRPS for comparing and interpreting the performance of the mechanisms, since this captures the most important properties for the causal model.
--- Node Shopping Event?
- The KL divergence between generated and observed distribution is 0.019221919686426836.
The estimated KL divergence indicates an overall very good representation of the data distribution.
--- Node Unit Price
- The MSE is 156.48090806251736.
- The NMSE is 0.6938977880013996.
- The R2 coefficient is 0.35194776992616694.
- The normalized CRPS is 0.12553014444452665.
The estimated CRPS indicates a very good model performance.
The mechanism is better or equally good than all 7 baseline mechanisms.
--- Node Ad Spend
- The MSE is 16677.202023167338.
- The NMSE is 0.48344956888514795.
- The R2 coefficient is 0.7512082042758019.
- The normalized CRPS is 0.2720127266162416.
The estimated CRPS indicates a good model performance.
The mechanism is better or equally good than all 7 baseline mechanisms.
--- Node Page Views
- The MSE is 77900.05479452056.
- The NMSE is 0.3462130891886136.
- The R2 coefficient is 0.7335844848896803.
- The normalized CRPS is 0.1803592381314227.
The estimated CRPS indicates a very good model performance.
The mechanism is better or equally good than all 7 baseline mechanisms.
--- Node Sold Units
- The MSE is 8758.161643835618.
- The NMSE is 0.1340557695877285.
- The R2 coefficient is 0.981600440084566.
- The normalized CRPS is 0.056745468190872575.
The estimated CRPS indicates a very good model performance.
The mechanism is better or equally good than all 7 baseline mechanisms.
--- Node Revenue
- The MSE is 1.7763093127296757e-19.
- The NMSE is 6.786229331465976e-16.
- The R2 coefficient is 1.0.
- The normalized CRPS is 1.4574679362932044e-16.
The estimated CRPS indicates a very good model performance.
The mechanism is better or equally good than all 7 baseline mechanisms.
--- Node Operational Cost
- The MSE is 38.48242630536858.
- The NMSE is 1.820517232232272e-05.
- The R2 coefficient is 0.9999999996455899.
- The normalized CRPS is 1.001979239428077e-05.
The estimated CRPS indicates a very good model performance.
The mechanism is better or equally good than all 7 baseline mechanisms.
--- Node Profit
- The MSE is 1.5832322135199285e-18.
- The NMSE is 4.723810955181931e-15.
- The R2 coefficient is 1.0.
- The normalized CRPS is 3.157782102773924e-16.
The estimated CRPS indicates a very good model performance.
The mechanism is better or equally good than all 7 baseline mechanisms.
==== Evaluation of Generated Distribution ====
The overall average KL divergence between the generated and observed distribution is 1.0102049246719438
The estimated KL divergence indicates some mismatches between the distributions.
==== NOTE ====
Always double check the made model assumptions with respect to the graph structure and choice of causal mechanisms.
All these evaluations give some insight into the goodness of the causal model, but should not be overinterpreted, since some causal relationships can be intrinsically hard to model. Furthermore, many algorithms are fairly robust against misspecifications or poor performances of causal mechanisms.
The fitted causal mechanisms are fairly good representations of the data generation process, with some minor inaccuracies. However, this is to be expected given the small sample size and relatively small signal-to-noise ratio for many nodes. Most importantly, all the baseline mechanisms did not perform better, which is a good indicator that our model selection is appropriate. Based on the evaluation, we also do not reject the given causal graph.
The selection of baseline models can be configured as well. For more details, take a look at the corresponding evaluate_causal_model documentation.
Step 3: Answer causal questions#
Generate new samples#
Since we learned about the data generation process, we can also generate new samples:
[9]:
gcm.draw_samples(scm, num_samples=10)
[9]:
| Shopping Event? | Unit Price | Ad Spend | Page Views | Sold Units | Revenue | Operational Cost | Profit | |
|---|---|---|---|---|---|---|---|---|
| 0 | False | $999.00 | $1,226.62 | 11761 | 2355 | $2,352,645.00 | $1,678,734.40 | $673,910.60 |
| 1 | False | $999.00 | $1,452.27 | 11680 | 2309 | $2,306,691.00 | $1,655,963.89 | $650,727.11 |
| 2 | False | $999.00 | $1,258.09 | 11849 | 2357 | $2,354,643.00 | $1,679,769.27 | $674,873.73 |
| 3 | False | $999.00 | $1,392.70 | 11637 | 2335 | $2,332,665.00 | $1,668,898.80 | $663,766.20 |
| 4 | False | $999.00 | $1,217.63 | 11713 | 2311 | $2,308,689.00 | $1,656,722.94 | $651,966.06 |
| 5 | False | $999.00 | $1,100.55 | 11720 | 2333 | $2,330,667.00 | $1,667,603.33 | $663,063.67 |
| 6 | False | $989.76 | $1,240.77 | 11710 | 2394 | $2,369,495.96 | $1,698,243.13 | $671,252.83 |
| 7 | False | $999.00 | $1,173.21 | 11444 | 2709 | $2,706,291.00 | $1,855,673.43 | $850,617.57 |
| 8 | False | $999.00 | $1,326.60 | 11658 | 2350 | $2,347,650.00 | $1,676,334.74 | $671,315.26 |
| 9 | False | $999.00 | $1,409.23 | 11845 | 2372 | $2,369,628.00 | $1,687,412.42 | $682,215.58 |
We have drawn 10 samples from the joint distribution following the learned causal relationships.
What are the key factors influencing the variance in profit?#
At this point, we want to understand which factors drive changes in the Profit. Let us first have a closer look at the Profit over time. For this, we plot the Profit over time for 2021, where the produced plot shows the Profit in dollars on the Y-axis and the time on the X-axis.
[10]:
data_2021['Profit'].plot(ylabel='Profit in $', figsize=(15,5), rot=45)
[10]:
<Axes: xlabel='Date', ylabel='Profit in $'>
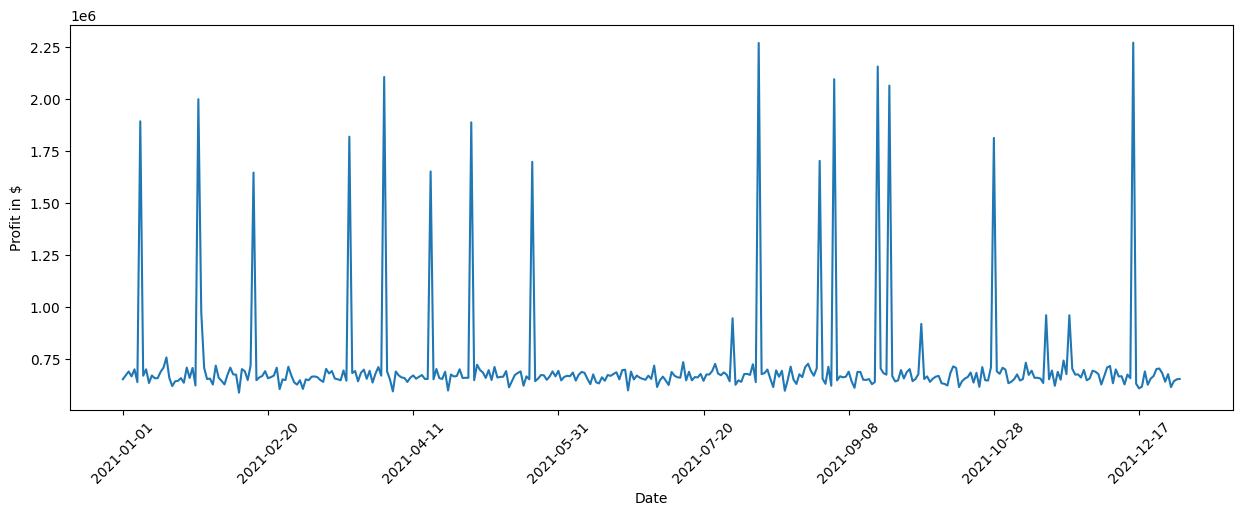
We see some significant spikes in the Profit across the year. We can further quantify this by looking at the standard deviation:
[11]:
data_2021['Profit'].std()
[11]:
The estimated standard deviation of ~259247 dollars is quite significant. Looking at the causal graph, we see that Revenue and Operational Cost have a direct impact on the Profit, but which of them contribute the most to the variance? To find this out, we can make use of the direct arrow strength algorithm that quantifies the causal influence of a specific arrow in the graph:
[12]:
import numpy as np
# Note: The percentage conversion only makes sense for purely positive attributions.
def convert_to_percentage(value_dictionary):
total_absolute_sum = np.sum([abs(v) for v in value_dictionary.values()])
return {k: abs(v) / total_absolute_sum * 100 for k, v in value_dictionary.items()}
arrow_strengths = gcm.arrow_strength(scm, target_node='Profit')
plot(causal_graph,
causal_strengths=convert_to_percentage(arrow_strengths),
figure_size=[15, 10])
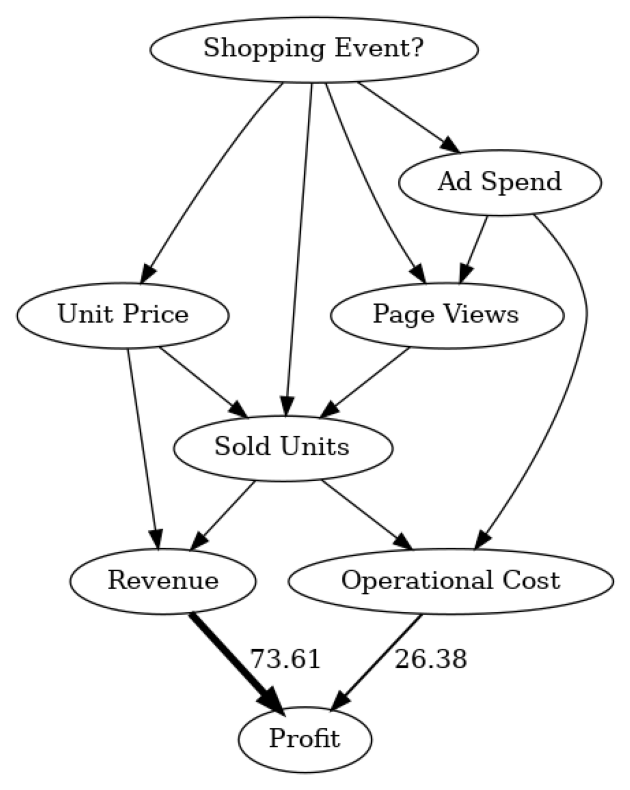
In this causal graph, we see how much each node contributes to the variance in Profit. For simplicity, the contributions are converted to percentages. Since Profit itself is only the difference between Revenue and Operational Cost, we do not expect further factors influencing the variance. As we see, Revenue has more impact than Operational Cost. This makes sense seeing that Revenue typically varies more than Operational Cost due to the stronger dependency on the number of sold units. Note that the direct arrow strength method also supports the use of other kinds of measures, for instance, KL divergence.
While the direct influences are helpful in understanding which direct parents influence the most on the variance in Profit, this mostly confirms our prior belief. The question of which factor is ultimately responsible for this high variance is, however, still unclear. For instance, Revenue itself is based on Sold Units and the Unit Price. Although we could recursively apply the direct arrow strength to all nodes, we would not get a correctly weighted insight into the influence of upstream nodes on the variance.
What are the important causal factors contributing to the variance in Profit? To find this out, we can use the intrinsic causal contribution method that attributes the variance in Profit to the upstream nodes in the causal graph by only considering information that is newly added by a node and not just inherited from its parents. For instance, a node that is simply a rescaled version of its parent would not have any intrinsic contribution. See the corresponding research paper for more details.
Let’s apply the method to the data:
[13]:
iccs = gcm.intrinsic_causal_influence(scm, target_node='Profit', num_samples_randomization=500)
Evaluating set functions...: 100%|██████████| 120/120 [02:37<00:00, 1.31s/it]
[14]:
from dowhy.utils import bar_plot
bar_plot(convert_to_percentage(iccs), ylabel='Variance attribution in %')
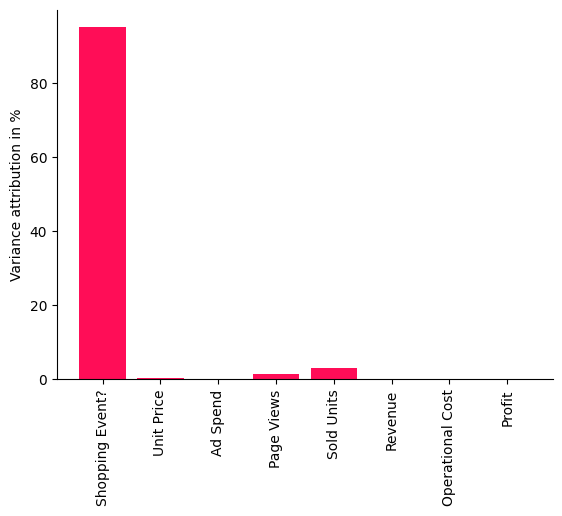
The scores shown in this bar chart are percentages indicating how much variance each node is contributing to Profit — without inheriting the variance from its parents in the causal graph. As we see quite clearly, the Shopping Event has by far the biggest influence on the variance in our Profit. This makes sense, seeing that the sales are heavily impacted during promotion periods like Black Friday or Prime Day and, thus, impact the overall profit. Surprisingly, we also see that factors such as the number of sold units or number of page views have a rather small influence, i.e., the large variance in profit can be almost completely explained by the shopping events. Let’s check this visually by marking the days where we had a shopping event. To do so, we use the pandas plot function again, but additionally mark all points in the plot with a vertical red bar where a shopping event occured:
[15]:
import matplotlib.pyplot as plt
data_2021['Profit'].plot(ylabel='Profit in $', figsize=(15,5), rot=45)
plt.vlines(np.arange(0, data_2021.shape[0])[data_2021['Shopping Event?']], data_2021['Profit'].min(), data_2021['Profit'].max(), linewidth=10, alpha=0.3, color='r')
[15]:
<matplotlib.collections.LineCollection at 0x7ff10016d460>
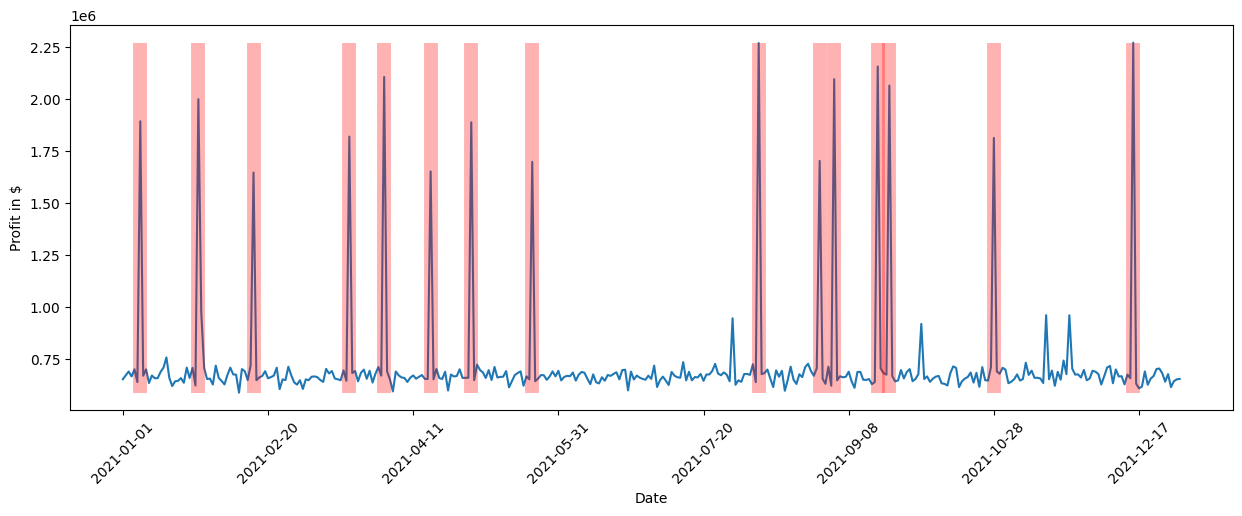
We clearly see that the shopping events coincide with the high peaks in profit. While we could have investigated this manually by looking at all kinds of different relationships or using domain knowledge, the tasks gets much more difficult as the complexity of the system increases. With a few lines of code, we obtained these insights from DoWhy.
What are the key factors explaining the Profit drop on a particular day?#
After a successful year in terms of profit, newer technologies come to the market and, thus, we want to keep the profit up and get rid of excess inventory by selling more devices. In order to increase the demand, we therefore lower the retail price by 10% at the beginning of 2022. Based on a prior analysis, we know that a decrease of 10% in the price would roughly increase the demand by 13.75%, a slight surplus. Following the price elasticity of demand model, we expect an increase of around 37.5% in number of Sold Units. Let us take a look if this is true by loading the data for the first day in 2022 and taking the fraction between the numbers of Sold Units from both years for that day:
[16]:
first_day_2022 = pd.read_csv('2022 First Day.csv', index_col='Date')
(first_day_2022['Sold Units'][0] / data_2021['Sold Units'][0] - 1) * 100
[16]:
Surprisingly, we only increased the number of sold units by ~19%. This will certainly impact the profit given that the revenue is much smaller than expected. Let us compare it with the previous year at the same time:
[17]:
(1 - first_day_2022['Profit'][0] / data_2021['Profit'][0]) * 100
[17]:
Indeed, the profit dropped by ~8.5%. Why is this the case seeing that we would expect a much higher demand due to the decreased price? Let us investigate what is going on here.
In order to figure out what contributed to the Profit drop, we can make use of DoWhy’s anomaly attribution feature. Here, we only need to specify the target node we are interested in (the Profit) and the anomaly sample we want to analyze (the first day of 2022). These results are then plotted in a bar chart indicating the attribution scores of each node for the given anomaly sample:
[18]:
attributions = gcm.attribute_anomalies(scm, target_node='Profit', anomaly_samples=first_day_2022)
bar_plot({k: v[0] for k, v in attributions.items()}, ylabel='Anomaly attribution score')
Evaluating set functions...: 100%|██████████| 125/125 [00:03<00:00, 38.58it/s]
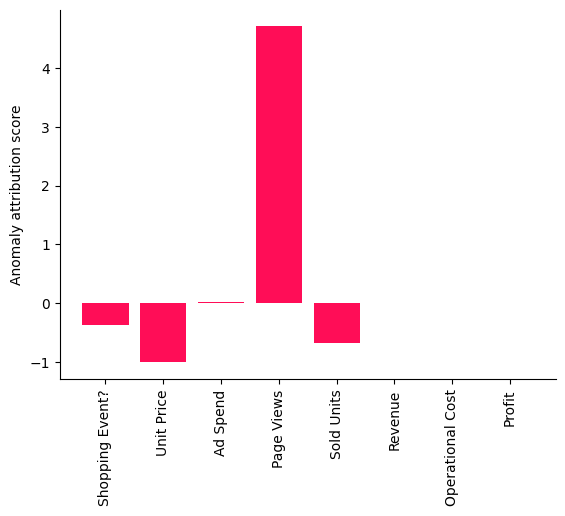
A positive attribution score means that the corresponding node contributed to the observed anomaly, which is in our case the drop in Profit. A negative score of a node indicates that the observed value for the node is actually reducing the likelihood of the anomaly (e.g., a higher demand due to the decreased price should increase the profit). More details about the interpretation of the score can be found in the corresponding reserach paper. Interestingly, the Page Views stand out as a factor explaining the Profit drop that day as indicated in the bar chart shown here.
While this method gives us a point estimate of the attributions for the particular models and parameters we learned, we can also use DoWhy’s confidence interval feature, which incorporates uncertainties about the fitted model parameters and algorithmic approximations:
[19]:
gcm.config.disable_progress_bars() # We turn off the progress bars here to reduce the number of outputs.
median_attributions, confidence_intervals, = gcm.confidence_intervals(
gcm.fit_and_compute(gcm.attribute_anomalies,
scm,
bootstrap_training_data=data_2021,
target_node='Profit',
anomaly_samples=first_day_2022),
num_bootstrap_resamples=10)
[20]:
bar_plot(median_attributions, confidence_intervals, 'Anomaly attribution score')
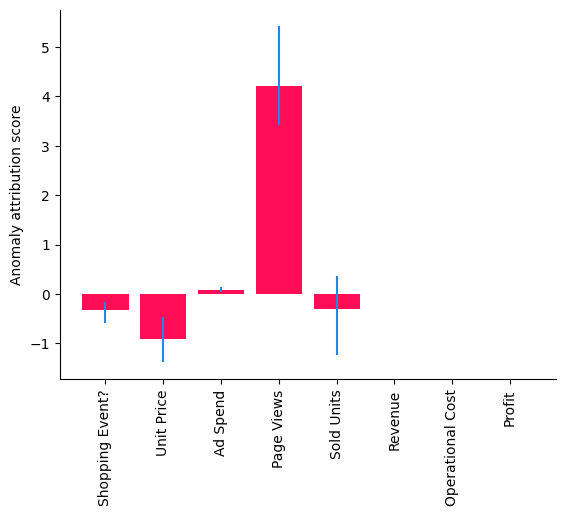
Note, in this bar chart we see the median attributions over multiple runs on smaller data sets, where each run re-fits the models and re-evaluates the attributions. We get a similar picture as before, but the confidence interval of the attribution to Sold Units also contains zero, meaning its contribution is insignificant. But some important questions still remain: Was this only a coincidence and, if not, which part in our system has changed? To find this out, we need to collect some more data.
Note that the results differ depending on the selected data, since they are sample specific. On other days, other factors could be relevant. Furthermore, note that the analysis (including the confidence intervals) always relies on the modeling assumptions made. In other words, if the models change or have a poor fit, one would also expect different results.
What caused the profit drop in Q1 2022?#
While the previous analysis is based on a single observation, let us see if this was just coincidence or if this is a persistent issue. When preparing the quarterly business report, we have some more data available from the first three months. We first check if the profit dropped on average in the first quarter of 2022 as compared to 2021. Similar as before, we can do this by taking the fraction between the average Profit of 2022 and 2021 for the first quarter:
[21]:
data_first_quarter_2021 = data_2021[data_2021.index <= '2021-03-31']
data_first_quarter_2022 = pd.read_csv("2022 First Quarter.csv", index_col='Date')
(1 - data_first_quarter_2022['Profit'].mean() / data_first_quarter_2021['Profit'].mean()) * 100
[21]:
Indeed, the profit drop is persistent in the first quarter of 2022. Now, what is the root cause of this? Let us apply the distribution change method to identify the part in the system that has changed:
[22]:
median_attributions, confidence_intervals = gcm.confidence_intervals(
lambda: gcm.distribution_change(scm,
data_first_quarter_2021,
data_first_quarter_2022,
target_node='Profit',
# Here, we are intersted in explaining the differences in the mean.
difference_estimation_func=lambda x, y: np.mean(y) - np.mean(x))
)
[23]:
bar_plot(median_attributions, confidence_intervals, 'Profit change attribution in $')
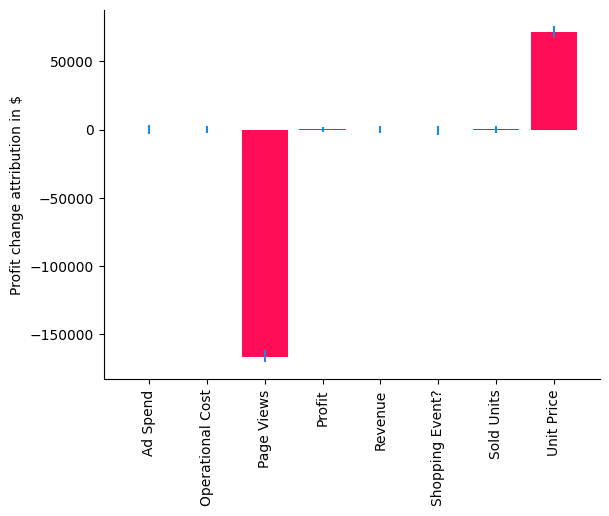
In our case, the distribution change method explains the change in the mean of Profit, i.e., a negative value indicates that a node contributes to a decrease and a positive value to an increase of the mean. Using the bar chart, we get now a very clear picture that the change in Unit Price has actually a slightly positive contribution to the expected Profit due to the increase of Sold Units, but it seems that the issue is coming from the Page Views which has a negative value. While we already understood this as a main driver of the drop at the beginning of 2022, we have now isolated and confirmed that something changed for the Page Views as well. Let’s compare the average Page Views with the previous year.
[24]:
(1 - data_first_quarter_2022['Page Views'].mean() / data_first_quarter_2021['Page Views'].mean()) * 100
[24]:
Indeed, the number of Page Views dropped by ~14%. Since we eliminated all other potential factors, we can now dive deeper into the Page Views and see what is going on there. This is a hypothetical scenario, but we could imagine it could be due to a change in the search algorithm which ranks this product lower in the results and therefore drives fewer customers to the product page. Knowing this, we could now start mitigating the issue.
Data generation process#
While the exact same data cannot be reproduced, the following dataset generator should provide quite similar types of data and has various parameters to adjust:
[25]:
from dowhy.datasets import sales_dataset
data_2021 = sales_dataset(start_date="2021-01-01", end_date="2021-12-31")
data_2022 = sales_dataset(start_date="2022-01-01", end_date="2022-12-31", change_of_price=0.9)