Basic Example for Graphical Causal Models#
Step 1: Modeling cause-effect relationships as a structural causal model (SCM)#
The first step is to model the cause-effect relationships between variables relevant to our use case. We do that in form of a causal graph. A causal graph is a directed acyclic graph (DAG) where an edge X→Y implies that X causes Y. Statistically, a causal graph encodes the conditional independence relations between variables. Using the NetworkX library, we can create causal graphs. In the snippet below, we create a chain X→Y→Z:
[1]:
import networkx as nx
causal_graph = nx.DiGraph([('X', 'Y'), ('Y', 'Z')])
To answer causal questions using causal graphs, we also have to know the nature of underlying data-generating process of variables. A causal graph by itself, being a diagram, does not have any information about the data-generating process. To introduce this data-generating process, we use an SCM that’s built on top of our causal graph:
[2]:
from dowhy import gcm
causal_model = gcm.StructuralCausalModel(causal_graph)
At this point we would normally load our dataset. For this introduction, we generate some synthetic data instead. The API takes data in form of Pandas DataFrames:
[3]:
import numpy as np, pandas as pd
X = np.random.normal(loc=0, scale=1, size=1000)
Y = 2 * X + np.random.normal(loc=0, scale=1, size=1000)
Z = 3 * Y + np.random.normal(loc=0, scale=1, size=1000)
data = pd.DataFrame(data=dict(X=X, Y=Y, Z=Z))
data.head()
[3]:
| X | Y | Z | |
|---|---|---|---|
| 0 | -0.748585 | -2.775036 | -5.522909 |
| 1 | 0.304654 | 0.606429 | 1.369306 |
| 2 | -0.214986 | -1.052285 | -3.247393 |
| 3 | -1.057319 | -3.664262 | -10.329441 |
| 4 | -1.875360 | -3.642252 | -12.891059 |
Note how the columns X, Y, Z correspond to our nodes X, Y, Z in the graph constructed above. We can also see how the values of X influence the values of Y and how the values of Y influence the values of Z in that data set.
The causal model created above allows us now to assign causal mechanisms to each node in the form of functional causal models. Here, these mechanism can either be assigned manually if, for instance, prior knowledge about certain causal relationships are known or they can be assigned automatically using the auto module. For the latter, we simply call:
[4]:
auto_assignment_summary = gcm.auto.assign_causal_mechanisms(causal_model, data)
Optionally, we can get more insights from the auto assignment process:
[5]:
print(auto_assignment_summary)
When using this auto assignment function, the given data is used to automatically assign a causal mechanism to each node. Note that causal mechanisms can also be customized and assigned manually.
The following types of causal mechanisms are considered for the automatic selection:
If root node:
An empirical distribution, i.e., the distribution is represented by randomly sampling from the provided data. This provides a flexible and non-parametric way to model the marginal distribution and is valid for all types of data modalities.
If non-root node and the data is continuous:
Additive Noise Models (ANM) of the form X_i = f(PA_i) + N_i, where PA_i are the parents of X_i and the unobserved noise N_i is assumed to be independent of PA_i.To select the best model for f, different regression models are evaluated and the model with the smallest mean squared error is selected.Note that minimizing the mean squared error here is equivalent to selecting the best choice of an ANM.
If non-root node and the data is discrete:
Discrete Additive Noise Models have almost the same definition as non-discrete ANMs, but come with an additional constraint for f to only return discrete values.
Note that 'discrete' here refers to numerical values with an order. If the data is categorical, consider representing them as strings to ensure proper model selection.
If non-root node and the data is categorical:
A functional causal model based on a classifier, i.e., X_i = f(PA_i, N_i).
Here, N_i follows a uniform distribution on [0, 1] and is used to randomly sample a class (category) using the conditional probability distribution produced by a classification model.Here, different model classes are evaluated using the (negative) F1 score and the best performing model class is selected.
In total, 3 nodes were analyzed:
--- Node: X
Node X is a root node. Therefore, assigning 'Empirical Distribution' to the node representing the marginal distribution.
--- Node: Y
Node Y is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using LinearRegression' to the node.
This represents the causal relationship as Y := f(X) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
LinearRegression: 0.9800842672468573
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 0.9838556091349311
HistGradientBoostingRegressor: 1.1417205950883154
--- Node: Z
Node Z is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using LinearRegression' to the node.
This represents the causal relationship as Z := f(Y) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
LinearRegression: 0.967971347157131
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 0.9711734724588762
HistGradientBoostingRegressor: 1.4150521077422746
===Note===
Note, based on the selected auto assignment quality, the set of evaluated models changes.
For more insights toward the quality of the fitted graphical causal model, consider using the evaluate_causal_model function after fitting the causal mechanisms.
In case we want to have more control over the assigned mechanisms, we can do this manually as well. For instance, we can can assign an empirical distribution to the root node X and linear additive noise models to nodes Y and Z:
[6]:
causal_model.set_causal_mechanism('X', gcm.EmpiricalDistribution())
causal_model.set_causal_mechanism('Y', gcm.AdditiveNoiseModel(gcm.ml.create_linear_regressor()))
causal_model.set_causal_mechanism('Z', gcm.AdditiveNoiseModel(gcm.ml.create_linear_regressor()))
Here, we set node X to follow the empirical distribution we observed (nonparametric) and nodes Y and Z to follow an additive noise model where we explicitly set a linear relationship.
In the real world, the data comes as an opaque stream of values, where we typically don’t know how one variable influences another. The graphical causal models can help us to deconstruct these causal relationships again, even though we didn’t know them before.
Step 2: Fitting the SCM to the data#
With the data at hand and the graph constructed earlier, we can now train the SCM using fit:
[7]:
gcm.fit(causal_model, data)
Fitting causal mechanism of node Z: 100%|██████████| 3/3 [00:00<00:00, 517.77it/s]
Fitting means, we learn the generative models of the variables in the SCM according to the data.
Once fitted, we can also obtain more insights into the model performances:
[8]:
print(gcm.evaluate_causal_model(causal_model, data))
Evaluating causal mechanisms...: 100%|██████████| 3/3 [00:00<00:00, 3930.93it/s]
Test permutations of given graph: 100%|██████████| 6/6 [00:00<00:00, 19.98it/s]
Evaluated the performance of the causal mechanisms and the invertibility assumption of the causal mechanisms and the overall average KL divergence between generated and observed distribution and the graph structure. The results are as follows:
==== Evaluation of Causal Mechanisms ====
The used evaluation metrics are:
- KL divergence (only for root-nodes): Evaluates the divergence between the generated and the observed distribution.
- Mean Squared Error (MSE): Evaluates the average squared differences between the observed values and the conditional expectation of the causal mechanisms.
- Normalized MSE (NMSE): The MSE normalized by the standard deviation for better comparison.
- R2 coefficient: Indicates how much variance is explained by the conditional expectations of the mechanisms. Note, however, that this can be misleading for nonlinear relationships.
- F1 score (only for categorical non-root nodes): The harmonic mean of the precision and recall indicating the goodness of the underlying classifier model.
- (normalized) Continuous Ranked Probability Score (CRPS): The CRPS generalizes the Mean Absolute Percentage Error to probabilistic predictions. This gives insights into the accuracy and calibration of the causal mechanisms.
NOTE: Every metric focuses on different aspects and they might not consistently indicate a good or bad performance.
We will mostly utilize the CRPS for comparing and interpreting the performance of the mechanisms, since this captures the most important properties for the causal model.
--- Node X
- The KL divergence between generated and observed distribution is 0.01649976739835941.
The estimated KL divergence indicates an overall very good representation of the data distribution.
--- Node Y
- The MSE is 0.9815044724137867.
- The NMSE is 0.45008485875858045.
- The R2 coefficient is 0.7964232578341484.
- The normalized CRPS is 0.25767351203525335.
The estimated CRPS indicates a good model performance.
--- Node Z
- The MSE is 0.9744960250422121.
- The NMSE is 0.14769619730165157.
- The R2 coefficient is 0.9781428218637729.
- The normalized CRPS is 0.08464191146545343.
The estimated CRPS indicates a very good model performance.
==== Evaluation of Invertible Functional Causal Model Assumption ====
--- The model assumption for node Y is not rejected with a p-value of 1.0 (after potential adjustment) and a significance level of 0.05.
This implies that the model assumption might be valid.
--- The model assumption for node Z is not rejected with a p-value of 1.0 (after potential adjustment) and a significance level of 0.05.
This implies that the model assumption might be valid.
Note that these results are based on statistical independence tests, and the fact that the assumption was not rejected does not necessarily imply that it is correct. There is just no evidence against it.
==== Evaluation of Generated Distribution ====
The overall average KL divergence between the generated and observed distribution is 0.025964440393727767
The estimated KL divergence indicates an overall very good representation of the data distribution.
==== Evaluation of the Causal Graph Structure ====
+-------------------------------------------------------------------------------------------------------+
| Falsification Summary |
+-------------------------------------------------------------------------------------------------------+
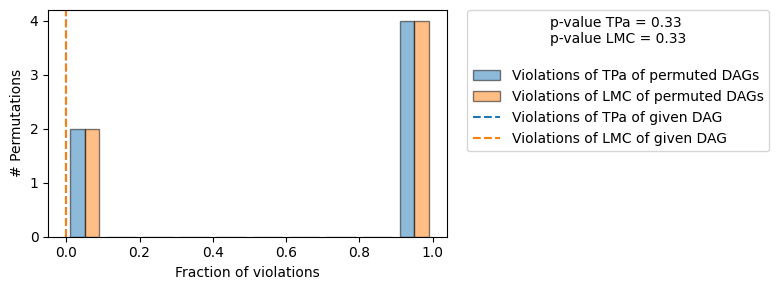
| The given DAG is not informative because 2 / 6 of the permutations lie in the Markov |
| equivalence class of the given DAG (p-value: 0.33). |
| The given DAG violates 0/1 LMCs and is better than 66.7% of the permuted DAGs (p-value: 0.33). |
| Based on the provided significance level (0.2) and because the DAG is not informative, |
| we do not reject the DAG. |
+-------------------------------------------------------------------------------------------------------+
==== NOTE ====
Always double check the made model assumptions with respect to the graph structure and choice of causal mechanisms.
All these evaluations give some insight into the goodness of the causal model, but should not be overinterpreted, since some causal relationships can be intrinsically hard to model. Furthermore, many algorithms are fairly robust against misspecifications or poor performances of causal mechanisms.
This summary tells us a few things: - Our models are a good fit. - The additive noise model assumption was not rejected. - The generated distribution is very similar to the observed one. - The causal graph structure was not rejected.
Note, this evaluation can take some significant time depending on the model complexities, graph size and amount of data. For a speed-up, consider changing the evaluation parameters.
Step 3: Answering a causal query based on the SCM#
The last step, answering a causal question, is our actual goal. E.g. we could ask the question “What will happen to the variable Z if I intervene on Y?”.
This can be done via the interventional_samples function. Here’s how:
[9]:
samples = gcm.interventional_samples(causal_model,
{'Y': lambda y: 2.34 },
num_samples_to_draw=1000)
samples.head()
[9]:
| X | Y | Z | |
|---|---|---|---|
| 0 | -0.416965 | 2.34 | 6.447330 |
| 1 | -0.389357 | 2.34 | 4.558476 |
| 2 | -0.167646 | 2.34 | 6.304203 |
| 3 | -0.114846 | 2.34 | 5.991273 |
| 4 | -1.158345 | 2.34 | 7.103817 |
This intervention says: “I’ll ignore any causal effects of X on Y, and set every value of Y to 2.34.” So the distribution of X will remain unchanged, whereas values of Y will be at a fixed value and Z will respond according to its causal model.
DoWhy offers a wide range of causal questions that can be answered with GCMs. See the user guide or other notebooks for more examples.