Basic Example for Calculating the Causal Effect#
This is a quick introduction to the DoWhy causal inference library. We will load in a sample dataset and estimate the causal effect of a (pre-specified) treatment variable on a (pre-specified) outcome variable.
First, let us load all required packages.
[1]:
import numpy as np
from dowhy import CausalModel
import dowhy.datasets
Now, let us load a dataset. For simplicity, we simulate a dataset with linear relationships between common causes and treatment, and common causes and outcome.
Beta is the true causal effect.
[2]:
data = dowhy.datasets.linear_dataset(beta=10,
num_common_causes=5,
num_instruments = 2,
num_effect_modifiers=1,
num_samples=5000,
treatment_is_binary=True,
stddev_treatment_noise=10,
num_discrete_common_causes=1)
df = data["df"]
[3]:
df.head()
[3]:
| X0 | Z0 | Z1 | W0 | W1 | W2 | W3 | W4 | v0 | y | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.229215 | 1.0 | 0.803310 | 0.969484 | 0.708693 | -0.472480 | 1.134963 | 0 | True | 11.467510 |
| 1 | -1.424967 | 0.0 | 0.163824 | -0.161973 | -0.495899 | -0.971206 | -0.177170 | 0 | False | -2.703782 |
| 2 | 0.462122 | 1.0 | 0.287209 | 2.114670 | -1.484899 | -0.760696 | 1.512796 | 1 | True | 13.401639 |
| 3 | -2.460213 | 0.0 | 0.188397 | 0.524076 | 0.090692 | -1.059184 | -1.477797 | 1 | False | 0.378057 |
| 4 | -2.152985 | 1.0 | 0.276386 | 1.981324 | 0.648104 | -1.882990 | -0.061003 | 0 | True | 9.043652 |
Note that we are using a pandas dataframe to load the data. At present, DoWhy only supports pandas dataframe as input.
Interface 1 (recommended): Input causal graph#
We now input a causal graph in the GML graph format (recommended). You can also use the DOT format.
To create the causal graph for your dataset, you can use a tool like DAGitty that provides a GUI to construct the graph. You can export the graph string that it generates. The graph string is very close to the DOT format: just rename dag to digraph, remove newlines and add a semicolon after every line, to convert it to the DOT format and input to DoWhy.
[4]:
# With graph
model=CausalModel(
data = df,
treatment=data["treatment_name"],
outcome=data["outcome_name"],
graph=data["gml_graph"]
)
[5]:
model.view_model()
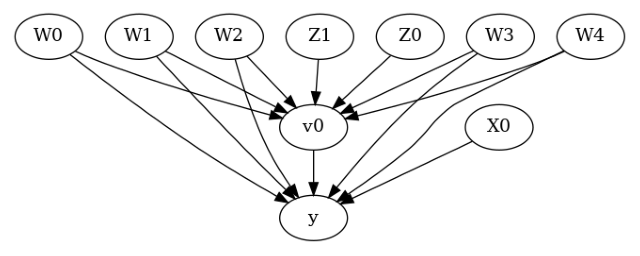
[6]:
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
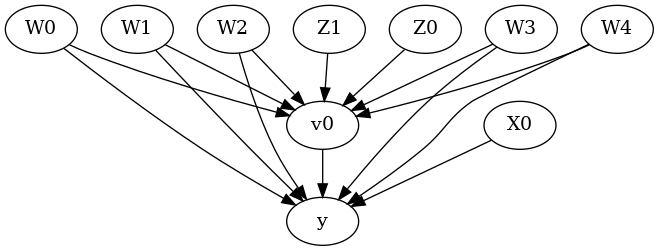
The above causal graph shows the assumptions encoded in the causal model. We can now use this graph to first identify the causal effect (go from a causal estimand to a probability expression), and then estimate the causal effect.
DoWhy philosophy: Keep identification and estimation separate#
Identification can be achieved without access to the data, acccesing only the graph. This results in an expression to be computed. This expression can then be evaluated using the available data in the estimation step. It is important to understand that these are orthogonal steps.
Identification#
[7]:
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W4,W1,W0,W2])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W4,W1,W0,W2,U) = P(y|v0,W3,W4,W1,W0,W2)
### Estimand : 2
Estimand name: iv
Estimand expression:
⎡ -1⎤
⎢ d ⎛ d ⎞ ⎥
E⎢─────────(y)⋅⎜─────────([v₀])⎟ ⎥
⎣d[Z₁ Z₀] ⎝d[Z₁ Z₀] ⎠ ⎦
Estimand assumption 1, As-if-random: If U→→y then ¬(U →→{Z1,Z0})
Estimand assumption 2, Exclusion: If we remove {Z1,Z0}→{v0}, then ¬({Z1,Z0}→y)
### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
Note the parameter flag proceed_when_unidentifiable. It needs to be set to True to convey the assumption that we are ignoring any unobserved confounding. The default behavior is to prompt the user to double-check that the unobserved confounders can be ignored.
Estimation#
[8]:
causal_estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification")
print(causal_estimate)
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W4,W1,W0,W2])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W4,W1,W0,W2,U) = P(y|v0,W3,W4,W1,W0,W2)
## Realized estimand
b: y~v0+W3+W4+W1+W0+W2
Target units: ate
## Estimate
Mean value: 9.666348684992126
You can input additional parameters to the estimate_effect method. For instance, to estimate the effect on any subset of the units, you can specify the “target_units” parameter which can be a string (“ate”, “att”, or “atc”), lambda function that filters rows of the data frame, or a new dataframe on which to compute the effect. You can also specify “effect modifiers” to estimate heterogeneous effects across these variables. See help(CausalModel.estimate_effect).
[9]:
# Causal effect on the control group (ATC)
causal_estimate_att = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification",
target_units = "atc")
print(causal_estimate_att)
print("Causal Estimate is " + str(causal_estimate_att.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W4,W1,W0,W2])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W4,W1,W0,W2,U) = P(y|v0,W3,W4,W1,W0,W2)
## Realized estimand
b: y~v0+W3+W4+W1+W0+W2
Target units: atc
## Estimate
Mean value: 9.670293023783838
Causal Estimate is 9.670293023783838
Interface 2: Specify common causes and instruments#
[10]:
# Without graph
model= CausalModel(
data=df,
treatment=data["treatment_name"],
outcome=data["outcome_name"],
common_causes=data["common_causes_names"],
effect_modifiers=data["effect_modifier_names"])
[11]:
model.view_model()
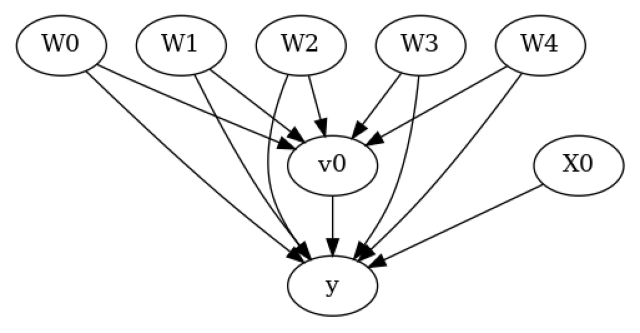
[12]:
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
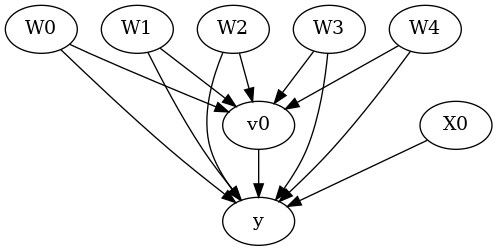
We get the same causal graph. Now identification and estimation is done as before.
[13]:
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
[14]:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification")
print(estimate)
print("Causal Estimate is " + str(estimate.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W4,W1,W0,W2])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W4,W1,W0,W2,U) = P(y|v0,W3,W4,W1,W0,W2)
## Realized estimand
b: y~v0+W3+W4+W1+W0+W2
Target units: ate
## Estimate
Mean value: 9.666348684992126
Causal Estimate is 9.666348684992126
Refuting the estimate#
Let us now look at ways of refuting the estimate obtained. Refutation methods provide tests that every correct estimator should pass. So if an estimator fails the refutation test (p-value is <0.05), then it means that there is some problem with the estimator.
Note that we cannot verify that the estimate is correct, but we can reject it if it violates certain expected behavior (this is analogous to scientific theories that can be falsified but not proven true). The below refutation tests are based on either 1) Invariant transformations: changes in the data that should not change the estimate. Any estimator whose result varies significantly between the original data and the modified data fails the test;
Random Common Cause
Data Subset
Nullifying transformations: after the data change, the causal true estimate is zero. Any estimator whose result varies significantly from zero on the new data fails the test.
Placebo Treatment
Adding a random common cause variable#
[15]:
res_random=model.refute_estimate(identified_estimand, estimate, method_name="random_common_cause", show_progress_bar=True)
print(res_random)
Refute: Add a random common cause
Estimated effect:9.666348684992126
New effect:9.66634868499213
p value:1.0
Replacing treatment with a random (placebo) variable#
[16]:
res_placebo=model.refute_estimate(identified_estimand, estimate,
method_name="placebo_treatment_refuter", show_progress_bar=True, placebo_type="permute")
print(res_placebo)
Refute: Use a Placebo Treatment
Estimated effect:9.666348684992126
New effect:0.029698445089780416
p value:0.94
Removing a random subset of the data#
[17]:
res_subset=model.refute_estimate(identified_estimand, estimate,
method_name="data_subset_refuter", show_progress_bar=True, subset_fraction=0.9)
print(res_subset)
Refute: Use a subset of data
Estimated effect:9.666348684992126
New effect:9.702493576161388
p value:0.5800000000000001
As you can see, the propensity score stratification estimator is reasonably robust to refutations.
Reproducability: For reproducibility, you can add a parameter “random_seed” to any refutation method, as shown below.
Parallelization: You can also use built-in parallelization to speed up the refutation process. Simply set n_jobs to a value greater than 1 to spread the workload to multiple CPUs, or set n_jobs=-1 to use all CPUs. Currently, this is available only for random_common_cause, placebo_treatment_refuter, and data_subset_refuter.
[18]:
res_subset=model.refute_estimate(identified_estimand, estimate,
method_name="data_subset_refuter", show_progress_bar=True, subset_fraction=0.9, random_seed = 1, n_jobs=-1, verbose=10)
print(res_subset)
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done 5 tasks | elapsed: 3.1s
[Parallel(n_jobs=-1)]: Done 10 tasks | elapsed: 3.6s
[Parallel(n_jobs=-1)]: Done 17 tasks | elapsed: 4.4s
[Parallel(n_jobs=-1)]: Done 24 tasks | elapsed: 4.9s
[Parallel(n_jobs=-1)]: Done 33 tasks | elapsed: 6.0s
[Parallel(n_jobs=-1)]: Done 42 tasks | elapsed: 6.9s
[Parallel(n_jobs=-1)]: Done 53 tasks | elapsed: 8.1s
[Parallel(n_jobs=-1)]: Done 64 tasks | elapsed: 9.1s
[Parallel(n_jobs=-1)]: Done 77 tasks | elapsed: 10.6s
[Parallel(n_jobs=-1)]: Done 90 tasks | elapsed: 12.0s
Refute: Use a subset of data
Estimated effect:9.666348684992126
New effect:9.701936861633671
p value:0.6000000000000001
[Parallel(n_jobs=-1)]: Done 100 out of 100 | elapsed: 12.9s finished
Adding an unobserved common cause variable#
This refutation does not return a p-value. Instead, it provides a sensitivity test on how quickly the estimate changes if the identifying assumptions (used in identify_effect) are not valid. Specifically, it checks sensitivity to violation of the backdoor assumption: that all common causes are observed.
To do so, it creates a new dataset with an additional common cause between treatment and outcome. To capture the effect of the common cause, the method takes as input the strength of common cause’s effect on treatment and outcome. Based on these inputs on the common cause’s effects, it changes the treatment and outcome values and then reruns the estimator. The hope is that the new estimate does not change drastically with a small effect of the unobserved common cause, indicating a robustness to any unobserved confounding.
Another equivalent way of interpreting this procedure is to assume that there was already unobserved confounding present in the input data. The change in treatment and outcome values removes the effect of whatever unobserved common cause was present in the original data. Then rerunning the estimator on this modified data provides the correct identified estimate and we hope that the difference between the new estimate and the original estimate is not too high, for some bounded value of the unobserved common cause’s effect.
Importance of domain knowledge: This test requires domain knowledge to set plausible input values of the effect of unobserved confounding. We first show the result for a single value of confounder’s effect on treatment and outcome.
[19]:
res_unobserved=model.refute_estimate(identified_estimand, estimate, method_name="add_unobserved_common_cause",
confounders_effect_on_treatment="binary_flip", confounders_effect_on_outcome="linear",
effect_strength_on_treatment=0.01, effect_strength_on_outcome=0.02)
print(res_unobserved)
Refute: Add an Unobserved Common Cause
Estimated effect:9.666348684992126
New effect:8.664434813571749
It is often more useful to inspect the trend as the effect of unobserved confounding is increased. For that, we can provide an array of hypothesized confounders’ effects. The output is the (min, max) range of the estimated effects under different unobserved confounding.
[20]:
res_unobserved_range=model.refute_estimate(identified_estimand, estimate, method_name="add_unobserved_common_cause",
confounders_effect_on_treatment="binary_flip", confounders_effect_on_outcome="linear",
effect_strength_on_treatment=np.array([0.001, 0.005, 0.01, 0.02]), effect_strength_on_outcome=0.01)
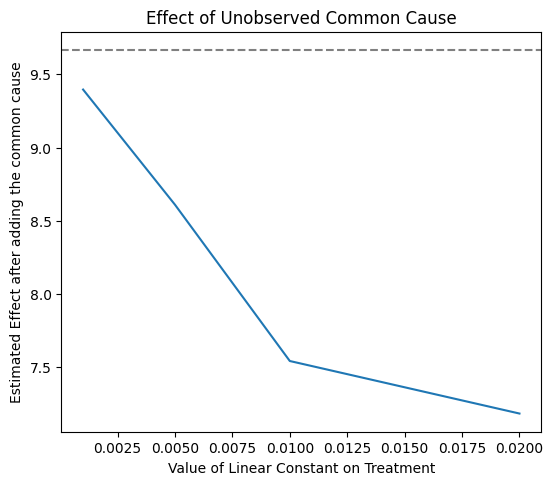
print(res_unobserved_range)
Refute: Add an Unobserved Common Cause
Estimated effect:9.666348684992126
New effect:(7.184834387565013, 9.395788216420343)
The above plot shows how the estimate decreases as the hypothesized confounding on treatment increases. By domain knowledge, we may know the maximum plausible confounding effect on treatment. Since we see that the effect does not go beyond zero, we can safely conclude that the causal effect of treatment v0 is positive.
We can also vary the confounding effect on both treatment and outcome. We obtain a heatmap.
[21]:
res_unobserved_range=model.refute_estimate(identified_estimand, estimate, method_name="add_unobserved_common_cause",
confounders_effect_on_treatment="binary_flip", confounders_effect_on_outcome="linear",
effect_strength_on_treatment=[0.001, 0.005, 0.01, 0.02],
effect_strength_on_outcome=[0.001, 0.005, 0.01,0.02])
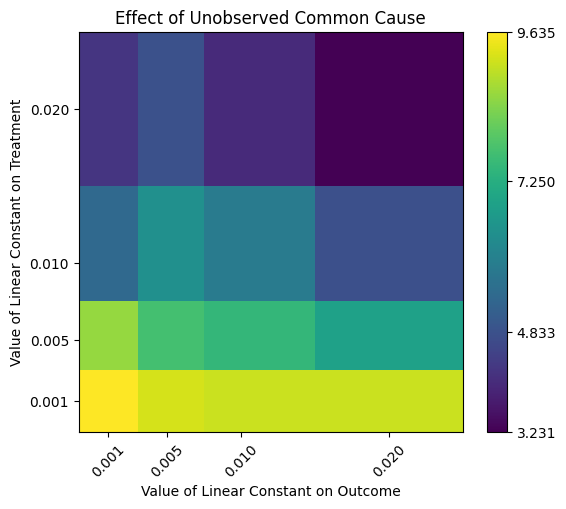
print(res_unobserved_range)
Refute: Add an Unobserved Common Cause
Estimated effect:9.666348684992126
New effect:(3.2311645505216724, 9.63495028468222)
Automatically inferring effect strength parameters. Finally, DoWhy supports automatic selection of the effect strength parameters. This is based on an assumption that the effect of the unobserved confounder on treatment or outcome cannot be stronger than that of any observed confounder. That is, we have collected data at least for the most relevant confounder. If that is the case, then we can bound the range of effect_strength_on_treatment and effect_strength_on_outcome by the effect
strength of observed confounders. There is an additional optional parameter signifying whether the effect strength of unobserved confounder should be as high as the highest observed, or a fraction of it. You can set it using the optional effect_fraction_on_treatment and effect_fraction_on_outcome parameters. By default, these two parameters are 1.
[22]:
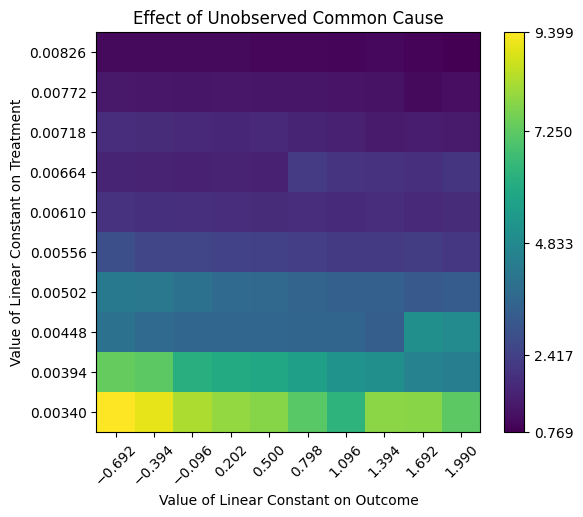
res_unobserved_auto = model.refute_estimate(identified_estimand, estimate, method_name="add_unobserved_common_cause",
confounders_effect_on_treatment="binary_flip", confounders_effect_on_outcome="linear")
print(res_unobserved_auto)
/github/home/.cache/pypoetry/virtualenvs/dowhy-oN2hW5jr-py3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:1183: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Refute: Add an Unobserved Common Cause
Estimated effect:9.666348684992126
New effect:(0.7690576672487185, 9.398648715588278)
Conclusion: Assuming that the unobserved confounder does not affect the treatment or outcome more strongly than any observed confounder, the causal effect can be concluded to be positive.