Causal attribution to sales growth and spend intervention#
The Scenario#
Suppose we have an advertiser selling products online. To promote sales, they give out discounts through price promotions, and advertise online through both display ads and sponsored ads in search results pages. To prepare for an upcoming business review, the advertiser compares 2024 and 2023 data and observes steady KPI growth such as sales, and product page views. However, the analytics team wonders what factors drive that growth, is it advertising, price promotion, or simply organic growth due to shopper trends? Answers to this question are key to understanding past growth. Furthermore, this advertiser wants actionable suggestions for business planning, such as spending on areas with higher returns on investment to double down next. In the following scenario, we will use DoWhy two-fold: first to causally attribute KPI growth drivers properly, so the analytics team understands what fueled past growth in a data-driven way. Second, we conduct interventions based on causal impact estimates to derive incremental return on investment (iROI), so the advertiser can forecast future KPI growth with additional investment. These factors and KPIs are:
dsp_spend: Ad spend on Demand Side Platform (DSP) through display ads
sp_spend: Ad spend on search results pages to bump up product rankings for easy discovery
discount: Discounts given through price reductions
special_shopping_event: A binary variable indicating whether a shopping event hosted by the ecommerce platform took place, such as Black Friday or Cyber Monday
other_shopping_event: A binary variable indicating other shopping events off the ecommerce platform. It can be from the advertiser itself, or its advertising with other platforms.
dpv: Number of product detail page views
sale: Daily revenue on the focal ecommerce platform
[1]:
import dowhy
dowhy.enable_notebook_rendering()
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
import pandas as pd
from functools import partial
from dowhy import gcm
from dowhy.utils.plotting import plot
from scipy import stats
from statsmodels.stats.multitest import multipletests
gcm.util.general.set_random_seed(0)
%matplotlib inline
1. Explore the data#
First, let’s load our data representing the spending, discounts, sale and other information for 2023 and 2024. Note that for this simulated data, we didn’t change the distribution of price discounts over periods of comparison and shouldn’t detect as such in the later attribution model.
[2]:
df = pd.read_csv('datasets/sales_attribution.csv', index_col=0)
df.head()
[2]:
| dsp_spend | sp_spend | dpv | discount | sale | activity_date | year | quarter | month | special_shopping_event | other_shopping_event | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11864.799390 | 2609.702789 | 54954.823150 | 26167.824599 | 76740.886670 | 2023-01-01 | 2023 | 1 | 1 | No | No |
| 1 | 11084.057110 | 2568.540570 | 44907.063324 | 22340.009780 | 52480.718941 | 2023-01-02 | 2023 | 1 | 1 | No | No |
| 2 | 16680.850945 | 2847.576700 | 151643.912564 | 68301.747813 | 628062.966309 | 2023-01-03 | 2023 | 1 | 1 | No | No |
| 3 | 15473.576264 | 2788.515831 | 121173.343955 | 18906.050402 | 307547.583964 | 2023-01-04 | 2023 | 1 | 1 | No | No |
| 4 | 10308.414302 | 2523.591011 | 36234.267337 | 18198.689563 | 35602.101926 | 2023-01-05 | 2023 | 1 | 1 | No | No |
To causally attribute factors of interests to changes, we first need to define time periods for comparisons.
[3]:
def generate_new_old_dataframes(df, new_year, new_quarters, new_months, old_year, old_quarters, old_months):
# Filter new data based on year, quarters, and months
new_conditions = (df['year'] == new_year) & (df['quarter'].isin(new_quarters)) & (df['month'].isin(new_months))
df_new = df[new_conditions].copy()
# Filter old data based on year, quarters, and months
old_conditions = (df['year'] == old_year) & (df['quarter'].isin(old_quarters)) & (df['month'].isin(old_months))
df_old = df[old_conditions].copy()
return df_new, df_old
df_new, df_old = generate_new_old_dataframes(df, new_year=2024, new_quarters=[1,2], new_months=[1,2,3,4,5,6], old_year=2023, old_quarters=[1,2], old_months=[1,2,3,4,5,6])
Then we define cumulative distribution functions to eyeball changes in metrics across two periods. Let’s plot them:
[4]:
def plot_metric_distributions(df_new, df_old, metric_columns):
for metric_column in metric_columns:
fig, ax = plt.subplots()
kde_new = stats.gaussian_kde(df_new[metric_column].dropna())
kde_old = stats.gaussian_kde(df_old[metric_column].dropna())
x_range = np.linspace(
min(df_new[metric_column].min(), df_old[metric_column].min()),
max(df_new[metric_column].max(), df_old[metric_column].max()),
1000
)
ax.plot(x_range, kde_new(x_range), color='#FF6B6B', lw=2, label='After')
ax.plot(x_range, kde_old(x_range), color='#4ECDC4', lw=2, label='Before')
ax.fill_between(x_range, kde_new(x_range), alpha=0.3, color='#FF6B6B')
ax.fill_between(x_range, kde_old(x_range), alpha=0.3, color='#4ECDC4')
ax.set_xlabel(metric_column)
ax.set_ylabel('Density')
ax.set_title(f'Comparison of {metric_column} distribution')
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.grid(True, linestyle='--', alpha=0.7)
ax.legend(fontsize=10)
plt.tight_layout()
plt.show()
Here, we are interested in the ‘dpv’ and ‘sale’ variables.
[5]:
# Define KPI
metric_columns = ['dpv', 'sale']
plot_metric_distributions(df_new, df_old, metric_columns)
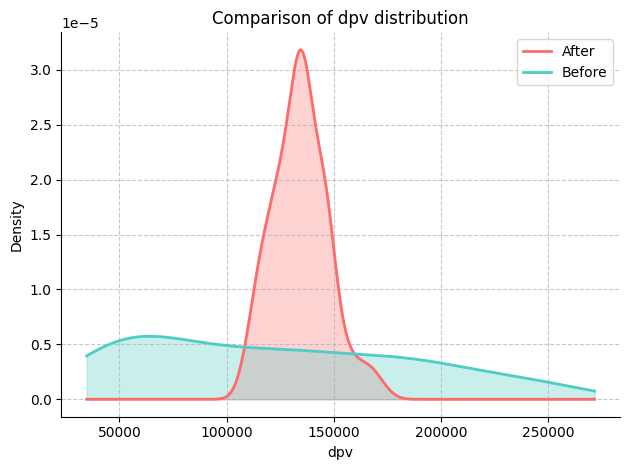
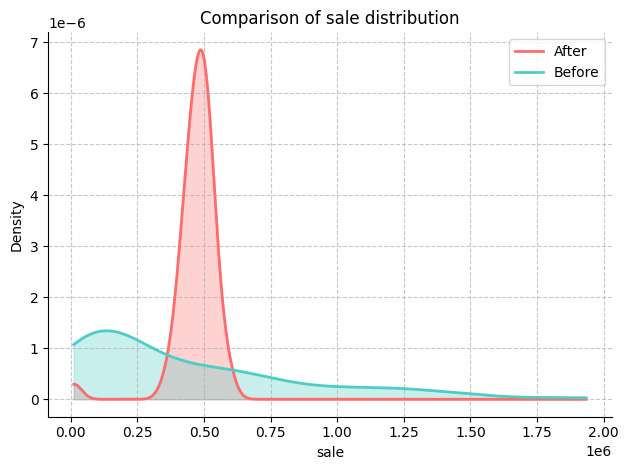
We can further quantify the magnitude of changes by comparing mean, median and variance of both KPIs and potential drivers.
[6]:
def compare_metrics(df_new, df_old, metrics):
comparison_data = []
for metric in metrics:
try:
mean_old = df_old[metric].mean()
median_old = df_old[metric].median()
variance_old = df_old[metric].var()
mean_new = df_new[metric].mean()
median_new = df_new[metric].median()
variance_new = df_new[metric].var()
if mean_old == 0:
print(f"Mean for {metric} in the old data is zero. Skipping mean change calculation.")
mean_change = None
else:
mean_change = ((mean_new - mean_old) / mean_old) * 100
if median_old == 0:
print(f"Median for {metric} in the old data is zero. Skipping median change calculation.")
median_change = None
else:
median_change = ((median_new - median_old) / median_old) * 100
if variance_old == 0:
print(f"Variance for {metric} in the old data is zero. Skipping variance change calculation.")
variance_change = None
else:
variance_change = ((variance_new - variance_old) / variance_old) * 100
comparison_data.append({
'Metric': metric,
'Δ mean': mean_change,
'Δ median': median_change,
'Δ variance': variance_change
})
except KeyError as e:
print(f"Metric {metric} not found in one of the DataFrames: {e}")
pass
comparison_df = pd.DataFrame(comparison_data)
return comparison_df
For simplicity, below we assume KPIs are revenue (sale), and product views (DPV), with potential drivers including ad spend on demand side platform (dsp_spend) and search results (sp_spend), and price promotion (discount).
[7]:
comparison_df = compare_metrics(df_new, df_old, ['sale', 'dpv', 'dsp_spend', 'sp_spend', 'discount'])
print(comparison_df)
Metric Δ mean Δ median Δ variance
0 sale 11.274001 84.089817 -95.972002
1 dpv 8.843596 12.453083 -95.913214
2 dsp_spend 6.387894 3.718354 -66.203836
3 sp_spend 10.335289 10.013358 312.605493
4 discount -1.837933 32.438169 -99.570962
2. Draw causal graph#
2.1.Set up basic causal graphs#
In the first step, we make use of our domain knowledge that all the ad investment and the shopping events can be potential causes of product page views and sale, but not vice versa. Further, detail page views can also lead to sales, regardless of ad investment.
[8]:
edges = []
for col in df.columns:
if 'spend' in col:
edges.append((col, 'dpv'))
edges.append((col, 'sale'))
edges.append(('special_shopping_event', 'dpv'))
edges.append(('other_shopping_event', 'dpv'))
edges.append(('special_shopping_event', 'sale'))
edges.append(('other_shopping_event', 'sale'))
edges.append(('discount', 'sale'))
edges.append(('dpv', 'sale'))
causal_graph = nx.DiGraph(edges)
[9]:
plot(causal_graph)
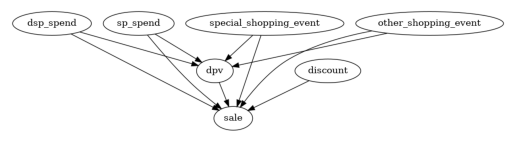
It is unlikely that all these edges are significant. Let’s prune some potential causes in the next step. This is to have a more refined causal graph. i.e, closer to the truth.
2.2. Prune nodes and edges#
One way to prune insignificant causal connections is conducting causal minimality tests through statistical dependence tests. The causality minimality test rules out any parent-child edge (\(X\to Y\)) for a node \(Y\) if \(Y\) is conditionally independent of \(X\) given other parents of \(Y\). If that is the case, node \(X\) does not provide additional information on top of the other parents of \(Y\). In layman’s language, some ads may not provide incremental information in the presence of others. Thus, we can remove those edges of \(X \to Y\). Note that the test is adjusted for multihypothesis testing to guarantee a consistent false discovery rate.
[10]:
def test_causal_minimality(graph, target, data, method='kernel', significance_level=0.10, fdr_control_method='fdr_bh'):
p_vals = []
all_parents = list(graph.predecessors(target))
for node in all_parents:
tmp_conditioning_set = list(all_parents)
tmp_conditioning_set.remove(node)
p_vals.append(gcm.independence_test(data[target].to_numpy(), data[node].to_numpy(), data[tmp_conditioning_set].to_numpy(), method=method))
if fdr_control_method is not None:
p_vals = multipletests(p_vals, significance_level, method=fdr_control_method)[1]
nodes_above_threshold = []
nodes_below_threshold = []
for i, node in enumerate(all_parents):
if p_vals[i] < significance_level:
nodes_above_threshold.append(node)
else:
nodes_below_threshold.append(node)
print("Significant connection:", [(n, target) for n in sorted(nodes_above_threshold)])
print("Insignificant connection:", [(n, target) for n in sorted(nodes_below_threshold)])
return sorted(nodes_below_threshold)
Then we remove insignificant edges and their associated nodes, resulting a refined causal graph.
[11]:
for insignificant_parent in test_causal_minimality(causal_graph, 'sale', df):
causal_graph.remove_edge(insignificant_parent, 'sale')
for insignificant_parent in test_causal_minimality(causal_graph, 'dpv', df):
causal_graph.remove_edge(insignificant_parent, 'dpv')
cols_to_remove=[]
cols_to_remove.extend([node for node in causal_graph.nodes if causal_graph.in_degree(node) + causal_graph.out_degree(node) == 0])
Significant connection: [('discount', 'sale'), ('dpv', 'sale'), ('dsp_spend', 'sale'), ('sp_spend', 'sale'), ('special_shopping_event', 'sale')]
Insignificant connection: [('other_shopping_event', 'sale')]
Significant connection: [('dsp_spend', 'dpv'), ('sp_spend', 'dpv')]
Insignificant connection: [('other_shopping_event', 'dpv'), ('special_shopping_event', 'dpv')]
[12]:
causal_graph.remove_nodes_from(set(cols_to_remove))
plot(causal_graph)
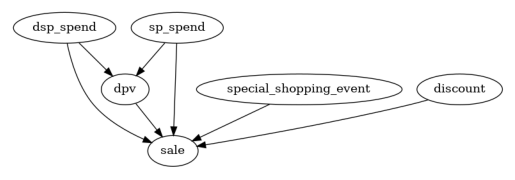
Interestingly, the ‘other_shopping_event’ variable has no significant impact on either ‘dpv’ or ‘sale’.
3. Fit causal graph#
Next, we need to assign functional causal models (FCMs) to each node, which describe the data generation process from x to y with an error term. The auto assignment method compares different prediction models for each node and takes the one with the smallest error. The quality parameter controls the set of model types that are tested, where BETTER indicates some of the most common regression and classification models, such as trees, support vector regression etc. You can also use
GOOD which fits fewer models to speed up, or BEST that is computationally heavy (and requres AutoGluon to be installed). After assigning the models, we can fit them to the data:
[13]:
causal_model = gcm.StructuralCausalModel(causal_graph)
[14]:
print(gcm.auto.assign_causal_mechanisms(causal_model, df, quality=gcm.auto.AssignmentQuality.BETTER))
When using this auto assignment function, the given data is used to automatically assign a causal mechanism to each node. Note that causal mechanisms can also be customized and assigned manually.
The following types of causal mechanisms are considered for the automatic selection:
If root node:
An empirical distribution, i.e., the distribution is represented by randomly sampling from the provided data. This provides a flexible and non-parametric way to model the marginal distribution and is valid for all types of data modalities.
If non-root node and the data is continuous:
Additive Noise Models (ANM) of the form X_i = f(PA_i) + N_i, where PA_i are the parents of X_i and the unobserved noise N_i is assumed to be independent of PA_i.To select the best model for f, different regression models are evaluated and the model with the smallest mean squared error is selected.Note that minimizing the mean squared error here is equivalent to selecting the best choice of an ANM.
If non-root node and the data is discrete:
Discrete Additive Noise Models have almost the same definition as non-discrete ANMs, but come with an additional constraint for f to only return discrete values.
Note that 'discrete' here refers to numerical values with an order. If the data is categorical, consider representing them as strings to ensure proper model selection.
If non-root node and the data is categorical:
A functional causal model based on a classifier, i.e., X_i = f(PA_i, N_i).
Here, N_i follows a uniform distribution on [0, 1] and is used to randomly sample a class (category) using the conditional probability distribution produced by a classification model. Here, different model classes are evaluated using the log loss metric and the best performing model class is selected.
In total, 6 nodes were analyzed:
--- Node: dsp_spend
Node dsp_spend is a root node. Therefore, assigning 'Empirical Distribution' to the node representing the marginal distribution.
--- Node: sp_spend
Node sp_spend is a root node. Therefore, assigning 'Empirical Distribution' to the node representing the marginal distribution.
--- Node: special_shopping_event
Node special_shopping_event is a root node. Therefore, assigning 'Empirical Distribution' to the node representing the marginal distribution.
--- Node: discount
Node discount is a root node. Therefore, assigning 'Empirical Distribution' to the node representing the marginal distribution.
--- Node: dpv
Node dpv is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using ExtraTreesRegressor' to the node.
This represents the causal relationship as dpv := f(dsp_spend,sp_spend) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
ExtraTreesRegressor: 166470642.14064425
RandomForestRegressor: 202413093.75654438
HistGradientBoostingRegressor: 210199781.95027882
AdaBoostRegressor: 277405500.13712883
KNeighborsRegressor: 367859348.3758382
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(include_bias=False)),
('linearregression', LinearRegression)]): 428084148.87153566
LinearRegression: 548678262.1828389
RidgeCV: 548678284.3329667
LassoCV(max_iter=10000): 557118490.7847294
SVR: 2900199761.6189833
--- Node: sale
Node sale is a non-root node with continuous data. Assigning 'AdditiveNoiseModel using ExtraTreesRegressor' to the node.
This represents the causal relationship as sale := f(discount,dpv,dsp_spend,sp_spend,special_shopping_event) + N.
For the model selection, the following models were evaluated on the mean squared error (MSE) metric:
ExtraTreesRegressor: 2332009300.2678514
RandomForestRegressor: 5154831913.930094
AdaBoostRegressor: 7802031657.73537
LinearRegression: 20252807738.720932
RidgeCV: 20398999697.143623
KNeighborsRegressor: 25224016431.708626
HistGradientBoostingRegressor: 29079555677.630787
LassoCV(max_iter=10000): 32196615412.165276
SVR: 134229564521.51865
===Note===
Note, based on the selected auto assignment quality, the set of evaluated models changes.
For more insights toward the quality of the fitted graphical causal model, consider using the evaluate_causal_model function after fitting the causal mechanisms.
[15]:
gcm.fit(causal_model, df)
Fitting causal mechanism of node discount: 100%|██████████| 6/6 [00:00<00:00, 23.79it/s]
4. Identify causal drivers for KPI changes#
To answer the question on drivers for past growth, we test if any of the potential drivers lead to KPI changes by comparing the data from 2023 and 2024. Below we quantify the contribution to changes in the mean of our KPI, but one can similarly estimate the contributions with respect to the median or variance etc.
[16]:
def calculate_difference_estimation(causal_model, df_old, df_new, target_column, difference_estimation_func, num_samples=2000, confidence_level=0.90, num_bootstrap_resamples=4):
difference_contribs, uncertainty_contribs = gcm.confidence_intervals(
lambda : gcm.distribution_change(causal_model,
df_old,
df_new,
target_column,
num_samples=num_samples,
difference_estimation_func=difference_estimation_func,
shapley_config=gcm.shapley.ShapleyConfig(approximation_method=gcm.shapley.ShapleyApproximationMethods.PERMUTATION, num_permutations=50)),
confidence_level=confidence_level,
num_bootstrap_resamples=num_bootstrap_resamples
)
return difference_contribs, uncertainty_contribs
median_diff_contribs, median_diff_uncertainty = calculate_difference_estimation(causal_model, df_old, df_new, 'sale', lambda x1, x2: np.mean(x2) - np.mean(x1))
Evaluating set functions...: 100%|██████████| 61/61 [00:01<00:00, 31.98it/s]
Evaluating set functions...: 100%|██████████| 62/62 [00:01<00:00, 33.10it/s]
Evaluating set functions...: 100%|██████████| 59/59 [00:01<00:00, 33.05it/s]
Evaluating set functions...: 100%|██████████| 62/62 [00:01<00:00, 33.10it/s]
Estimating bootstrap interval...: 100%|██████████| 4/4 [00:12<00:00, 3.23s/it]
Then we plot drivers’ contribution to KPI changes visually, followed by a tabular format.
[17]:
gcm.util.bar_plot(median_diff_contribs, median_diff_uncertainty, 'Contribution', figure_size=(10,5))
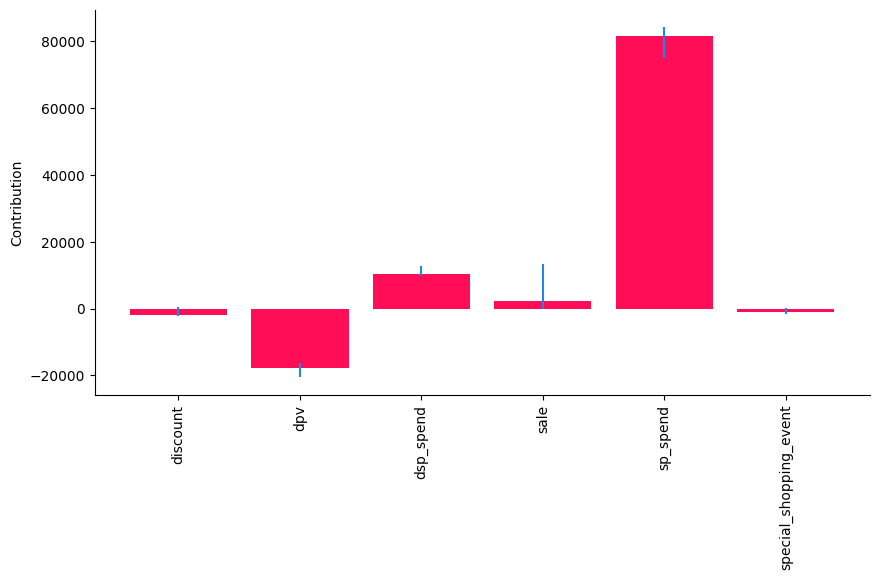
Here, we see that ‘sp_spend’ has the larges contribution to the change in the mean of ‘sale’, while the ‘discount’ and ‘special_shopping_event’ has little to none contribution. This aligns with the way how the data was generated.
Taking a look at the tabular overview to look for significance based on the confidence intervals:
[18]:
def show_tabular(median_contribs, uncertainty_contribs):
rows = []
for node, median_contrib in median_contribs.items():
rows.append(dict(node=node, median=median_contrib, lb=uncertainty_contribs[node][0], ub=uncertainty_contribs[node][1]))
df = pd.DataFrame(rows).set_index('node')
df.rename(columns=dict(median='median', lb='lb', ub='ub'), inplace=True)
return df
# show_tabular(median_contribs, uncertainty_contribs)
result_df = pd.DataFrame(show_tabular(median_diff_contribs, median_diff_uncertainty))
result_df
[18]:
| median | lb | ub | |
|---|---|---|---|
| node | |||
| discount | 404.249464 | -2541.978891 | 1871.992788 |
| dpv | -17030.755266 | -20822.520925 | -12808.318982 |
| dsp_spend | 13230.332551 | 8285.398025 | 15570.497543 |
| sale | 2385.261508 | -3828.367497 | 5810.297447 |
| sp_spend | 80356.934864 | 74540.709426 | 87494.532581 |
| special_shopping_event | -1105.261287 | -2518.043702 | 929.361176 |
Next, we remove all variables that have a 0 as part of their confidence interval or are negative, i.e., do not have a clear significant positive contribution:
[19]:
def filter_significant_rows(result_df, direction, ub_col, lb_col):
if direction == 'positive':
significant_rows = result_df[(result_df[ub_col] > 0) & (result_df[lb_col] > 0)]
elif direction == 'negative':
significant_rows = result_df[(result_df[ub_col] < 0) & (result_df[lb_col] < 0)]
else:
raise ValueError("Invalid direction. Choose 'positive' or 'negative'.")
return significant_rows
[20]:
positive_significant_rows = filter_significant_rows(result_df, 'positive', 'ub', 'lb')
positive_significant_rows
[20]:
| median | lb | ub | |
|---|---|---|---|
| node | |||
| dsp_spend | 13230.332551 | 8285.398025 | 15570.497543 |
| sp_spend | 80356.934864 | 74540.709426 | 87494.532581 |
This tells us, ‘dsp_spend’ and ‘sp_spend’ had a significantly positive contribution to the shift in ‘sale’.
5. Optimal intervention#
Section 4 above helps us to understand drivers for past growth. Now, looking forward to business planning, we conduct interventions to understand incremental contributions to KPIs. Intuitively, the spend types resulting in higher returns should be doubled down on. Here, we explicitly remove ‘sale’, ‘dpv’ and ‘special_shopping_event’ as a possible intervention targets.
[21]:
def intervention_influence(causal_model, target, step_size=1, non_interveneable_nodes=None, confidence_level=0.95, prints=False, threshold_insignificant=0.0001):
progress_bar_was_on = gcm.config.show_progress_bars
if progress_bar_was_on:
gcm.config.disable_progress_bars()
causal_effects = {}
causal_effects_confidence_interval = {}
capped_effects = []
if non_interveneable_nodes is None:
non_interveneable_nodes = []
for node in causal_model.graph.nodes:
if node in non_interveneable_nodes:
continue
# Define interventions
def intervention(x):
return x + step_size
def non_intervention(x):
return x
interventions_alternative = {node: intervention}
interventions_reference = {node: non_intervention}
effect = gcm.confidence_intervals(
partial(gcm.average_causal_effect,
causal_model=causal_model,
target_node=target,
interventions_alternative=interventions_alternative,
interventions_reference=interventions_reference,
num_samples_to_draw=10000),
n_jobs=-1,
num_bootstrap_resamples=40,
confidence_level=confidence_level)
causal_effects[node] = effect[0][0]
causal_effects_confidence_interval[node] = effect[1].squeeze()
# Apply non-negativity constraint - Here, spend cannot be negative. However, small negative values can happen in the analysis due to misspecifications.
if node.endswith('_spend') and causal_effects[node] < 0:
causal_effects[node] = 0
causal_effects_confidence_interval[node] = [np.nan, np.nan]
if progress_bar_was_on:
gcm.config.enable_progress_bars()
print(causal_effects)
if prints:
for node in sorted(causal_effects, key=causal_effects.get, reverse=True):
if abs(causal_effects[node]) < threshold_insignificant:
print(f"{'Increasing' if step_size > 0 else 'Decreasing'} {node} by {step_size} has no significant effect on {target}.")
else:
print(f"{'Increasing' if step_size > 0 else 'Decreasing'} {node} by {step_size} {'increases' if causal_effects[node] > 0 else 'decreases'} {target} "
f"by around {causal_effects[node]} with a confidence interval ({confidence_level * 100}%) of {causal_effects_confidence_interval[node]}.")
all_variables = list(causal_effects.keys())
all_causal_effects = [causal_effects[key] for key in all_variables]
all_lower_bounds = [causal_effects_confidence_interval[key][0] for key in all_variables]
all_upper_bounds = [causal_effects_confidence_interval[key][1] for key in all_variables]
result_df = pd.DataFrame({'Variable': all_variables,
'Causal Effect': all_causal_effects,
'Lower CI': all_lower_bounds,
'Upper CI': all_upper_bounds},
index = all_variables)
return result_df
[22]:
interv_result = intervention_influence(causal_model=causal_model, target='sale', non_interveneable_nodes=['dpv', 'sale', 'special_shopping_event'], prints=True)
interv_result
/home/runner/.cache/pypoetry/virtualenvs/dowhy-n6DJFijf-py3.9/lib/python3.9/site-packages/joblib/externals/loky/process_executor.py:782: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak.
warnings.warn(
{'dsp_spend': np.float64(17.24967418278742), 'sp_spend': np.float64(251.46429418905464), 'discount': np.float64(-0.3838008170953823)}
Increasing sp_spend by 1 increases sale by around 251.46429418905464 with a confidence interval (95.0%) of [189.23222528 297.30733219].
Increasing dsp_spend by 1 increases sale by around 17.24967418278742 with a confidence interval (95.0%) of [ 2.88751799 40.04585586].
Increasing discount by 1 decreases sale by around -0.3838008170953823 with a confidence interval (95.0%) of [-1.04614227 1.0169307 ].
[22]:
| Variable | Causal Effect | Lower CI | Upper CI | |
|---|---|---|---|---|
| dsp_spend | dsp_spend | 17.249674 | 2.887518 | 40.045856 |
| sp_spend | sp_spend | 251.464294 | 189.232225 | 297.307332 |
| discount | discount | -0.383801 | -1.046142 | 1.016931 |
We similarly filter to positively significant interventions, i.e., the spending with statistically significant positive returns. The interpretation is, for each dollar spent on one type of ad, we receive X amount in return, with X indicated in the ‘Causal Effect’ column.
[23]:
filter_significant_rows(interv_result, 'positive', 'Upper CI', 'Lower CI')
[23]:
| Variable | Causal Effect | Lower CI | Upper CI | |
|---|---|---|---|---|
| dsp_spend | dsp_spend | 17.249674 | 2.887518 | 40.045856 |
| sp_spend | sp_spend | 251.464294 | 189.232225 | 297.307332 |
This tells us that there is a clear benefit in doubling down on ‘sp_spend’ and ‘dsp_spend’. Note that the quantitative numbers here can be off due to model misspecifications, but they nevertheless provide some helpful insights.
Summary#
This advertiser comes to us to understand what drove past growth. Starting with a causal graph drawn from domain knowledge, we refined the graph to prune unnecessary nodes and edges. Then we fit a causal attribution model in Section 4 to test which types of investment changes lead to KPI growth. We find that increases in both dsp_spend and sp_spend contribute to KPIs growth in 2024 vs. 2023. This conclusion helps the analytics team to understand root causes of past sales growth. Looking forward to future budget planning, we conducted interventions to understand incremental return on investment (iROI), and identify those types of spend way above $1 to double down on.