DoWhy: Interpreters for Causal Estimators
This is a quick introduction to the use of interpreters in the DoWhy causal inference library. We will load in a sample dataset, use different methods for estimating the causal effect of a (pre-specified)treatment variable on a (pre-specified) outcome variable and demonstrate how to interpret the obtained results.
First, let us add the required path for Python to find the DoWhy code and load all required packages
[1]:
%load_ext autoreload
%autoreload 2
[2]:
import numpy as np
import pandas as pd
import logging
import dowhy
from dowhy import CausalModel
import dowhy.datasets
Now, let us load a dataset. For simplicity, we simulate a dataset with linear relationships between common causes and treatment, and common causes and outcome.
Beta is the true causal effect.
[3]:
data = dowhy.datasets.linear_dataset(beta=1,
num_common_causes=5,
num_instruments = 2,
num_treatments=1,
num_discrete_common_causes=1,
num_samples=10000,
treatment_is_binary=True,
outcome_is_binary=False)
df = data["df"]
print(df[df.v0==True].shape[0])
df
9087
[3]:
| Z0 | Z1 | W0 | W1 | W2 | W3 | W4 | v0 | y | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.274883 | 2.675104 | -0.735852 | 1.210690 | 2.450803 | 1 | True | 3.028806 |
| 1 | 0.0 | 0.822977 | -0.160337 | 0.992291 | 0.935095 | -0.290785 | 0 | True | 2.406981 |
| 2 | 0.0 | 0.040569 | -0.798407 | 0.415104 | 0.883029 | 0.461694 | 3 | True | 3.557867 |
| 3 | 0.0 | 0.535184 | 0.225968 | 1.204263 | -0.772000 | 0.616305 | 1 | True | 2.413301 |
| 4 | 0.0 | 0.396014 | -0.037411 | 0.041219 | -1.887850 | 0.014703 | 1 | False | -0.716963 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9995 | 0.0 | 0.099076 | -0.728865 | 1.764483 | -1.575695 | -0.454469 | 1 | True | 1.799262 |
| 9996 | 0.0 | 0.473974 | -0.053432 | -1.721870 | 1.080155 | 1.892096 | 3 | True | 2.393228 |
| 9997 | 1.0 | 0.024463 | 0.173962 | -0.108042 | -0.791984 | 0.018023 | 3 | False | 0.930023 |
| 9998 | 1.0 | 0.412206 | 0.715236 | 0.107234 | -1.121317 | 2.020074 | 0 | True | 1.263492 |
| 9999 | 0.0 | 0.512268 | 0.207495 | 0.093158 | 1.437145 | 0.361902 | 1 | True | 2.727700 |
10000 rows × 9 columns
Note that we are using a pandas dataframe to load the data.
Identifying the causal estimand
We now input a causal graph in the GML graph format.
[4]:
# With graph
model=CausalModel(
data = df,
treatment=data["treatment_name"],
outcome=data["outcome_name"],
graph=data["gml_graph"],
instruments=data["instrument_names"]
)
[5]:
model.view_model()
[6]:
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
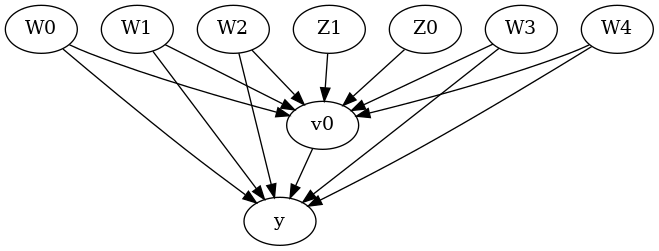
We get a causal graph. Now identification and estimation is done.
[7]:
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W1,W4,W2,W0])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W1,W4,W2,W0,U) = P(y|v0,W3,W1,W4,W2,W0)
### Estimand : 2
Estimand name: iv
Estimand expression:
⎡ -1⎤
⎢ d ⎛ d ⎞ ⎥
E⎢─────────(y)⋅⎜─────────([v₀])⎟ ⎥
⎣d[Z₁ Z₀] ⎝d[Z₁ Z₀] ⎠ ⎦
Estimand assumption 1, As-if-random: If U→→y then ¬(U →→{Z1,Z0})
Estimand assumption 2, Exclusion: If we remove {Z1,Z0}→{v0}, then ¬({Z1,Z0}→y)
### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
Method 1: Propensity Score Stratification
We will be using propensity scores to stratify units in the data.
[8]:
causal_estimate_strat = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification",
target_units="att")
print(causal_estimate_strat)
print("Causal Estimate is " + str(causal_estimate_strat.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W1,W4,W2,W0])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W1,W4,W2,W0,U) = P(y|v0,W3,W1,W4,W2,W0)
## Realized estimand
b: y~v0+W3+W1+W4+W2+W0
Target units: att
## Estimate
Mean value: 0.9716806691376662
Causal Estimate is 0.9716806691376662
Textual Interpreter
The textual Interpreter describes (in words) the effect of unit change in the treatment variable on the outcome variable.
[9]:
# Textual Interpreter
interpretation = causal_estimate_strat.interpret(method_name="textual_effect_interpreter")
Increasing the treatment variable(s) [v0] from 0 to 1 causes an increase of 0.9716806691376662 in the expected value of the outcome [['y']], over the data distribution/population represented by the dataset.
Visual Interpreter
The visual interpreter plots the change in the standardized mean difference (SMD) before and after Propensity Score based adjustment of the dataset. The formula for SMD is given below.
\(SMD = \frac{\bar X_{1} - \bar X_{2}}{\sqrt{(S_{1}^{2} + S_{2}^{2})/2}}\)
Here, \(\bar X_{1}\) and \(\bar X_{2}\) are the sample mean for the treated and control groups.
[10]:
# Visual Interpreter
interpretation = causal_estimate_strat.interpret(method_name="propensity_balance_interpreter")
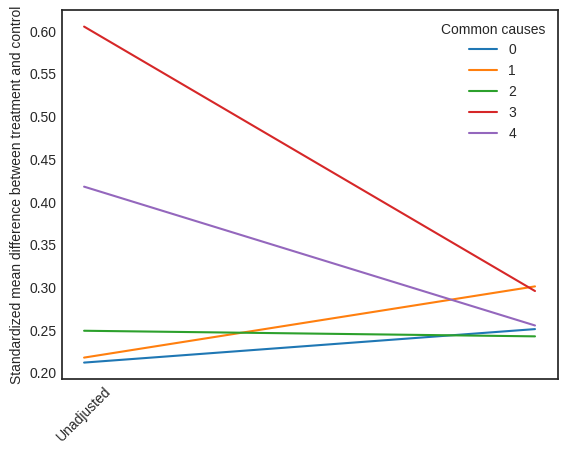
This plot shows how the SMD decreases from the unadjusted to the stratified units.
Method 2: Propensity Score Matching
We will be using propensity scores to match units in the data.
[11]:
causal_estimate_match = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_matching",
target_units="atc")
print(causal_estimate_match)
print("Causal Estimate is " + str(causal_estimate_match.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W1,W4,W2,W0])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W1,W4,W2,W0,U) = P(y|v0,W3,W1,W4,W2,W0)
## Realized estimand
b: y~v0+W3+W1+W4+W2+W0
Target units: atc
## Estimate
Mean value: 1.015044165024974
Causal Estimate is 1.015044165024974
[12]:
# Textual Interpreter
interpretation = causal_estimate_match.interpret(method_name="textual_effect_interpreter")
Increasing the treatment variable(s) [v0] from 0 to 1 causes an increase of 1.015044165024974 in the expected value of the outcome [['y']], over the data distribution/population represented by the dataset.
Cannot use propensity balance interpretor here since the interpreter method only supports propensity score stratification estimator.
Method 3: Weighting
We will be using (inverse) propensity scores to assign weights to units in the data. DoWhy supports a few different weighting schemes: 1. Vanilla Inverse Propensity Score weighting (IPS) (weighting_scheme=“ips_weight”) 2. Self-normalized IPS weighting (also known as the Hajek estimator) (weighting_scheme=“ips_normalized_weight”) 3. Stabilized IPS weighting (weighting_scheme = “ips_stabilized_weight”)
[13]:
causal_estimate_ipw = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_weighting",
target_units = "ate",
method_params={"weighting_scheme":"ips_weight"})
print(causal_estimate_ipw)
print("Causal Estimate is " + str(causal_estimate_ipw.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W3,W1,W4,W2,W0])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W3,W1,W4,W2,W0,U) = P(y|v0,W3,W1,W4,W2,W0)
## Realized estimand
b: y~v0+W3+W1+W4+W2+W0
Target units: ate
## Estimate
Mean value: 1.2661537836861554
Causal Estimate is 1.2661537836861554
[14]:
# Textual Interpreter
interpretation = causal_estimate_ipw.interpret(method_name="textual_effect_interpreter")
Increasing the treatment variable(s) [v0] from 0 to 1 causes an increase of 1.2661537836861554 in the expected value of the outcome [['y']], over the data distribution/population represented by the dataset.
[15]:
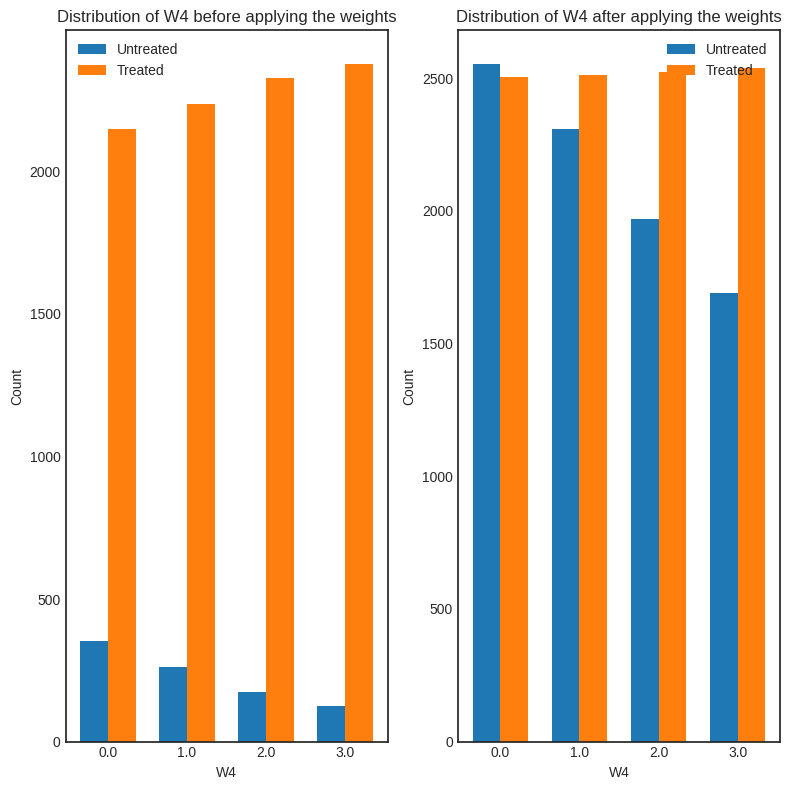
interpretation = causal_estimate_ipw.interpret(method_name="confounder_distribution_interpreter", fig_size=(8,8), font_size=12, var_name='W4', var_type='discrete')
[ ]: